Visual Features: KeyPoints and Descriptors
keypoints : (locally) distinct location in an image. noise, 회전, 크기 변환, 밝기 변환에 강인한 point. 이 조건에 맞는 특징점 중 하나를 코너점이라고 얘기할 수 있음. (cf. 코너점 : 상하좌우로 움직였을 때, 모두 큰 변화가 일어나는 곳)
Descriptors : keypoint를 설명하는 방식. 128개의 숫자. keypoint 주변의 local structure 요약
corners는 translation, rotation, illumination에 불변함.
corner : roughy orthogonal directions(직교방향)의 2개의 edges
edges : sudden brightness change
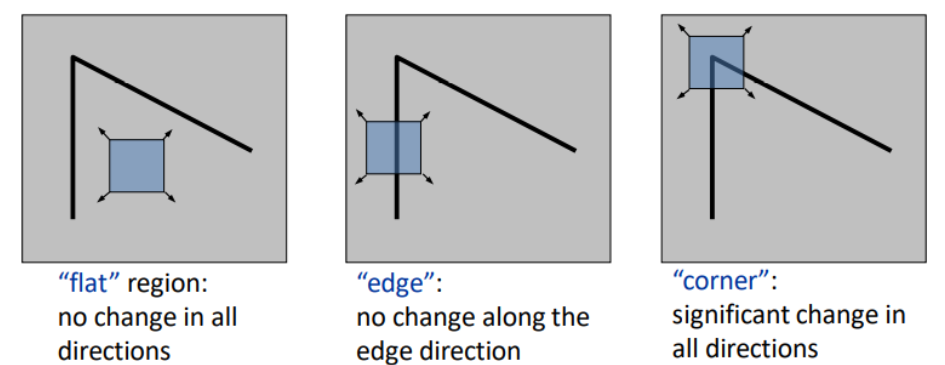
Finding Corners
- corners를 찾기 위해서, 우리는 two directions에서 intensity changes를 찾아야 함.
- (x, y) 주변의 neighbor pixel의 SSD(sum or squared differences of image intensity values of pixels under a given shift (du, dv))를 계산하면 변화의 정도를 알 수 있음.
하지만 모든 픽셀을 계산하는 것은 계산량이 너무 많아서 비효율적임. 따라서 제안된 것이 Taylor expansion
Taylor expansion이란 어떤 함수 f(x)를 다항함수로 근사시키는 것을 의미함.
Structure Matrix : first derivative에 대한 정보를 담고 잇는 식으로 edges와 corners를 찾아내는 key와 같은 역할 image gradients로부터 만들어짐. Computing the Structure Matrix - Jacobians는 Scharr 또는 Sobel과 같은 gradient kernel을 이용하여 convolution으로 계산됨. Harris, Shi-Tomasi & Forstner corner을 정의하기 위한 3개의 비슷한 연구들이 있었음. - 1987: Forstner- 1988: Harris- 1994: Shi-Tomasi 모든 연구는 sturcture matrix를 기반으로 point가 corner인지 아닌지 결정할 때 서로 다른 기준 (criterion) 사용 Fostner은 subpixel estimation 방법을 사용
수정 중인 글입니다.
'Machine Learning and Deep Learning' 카테고리의 다른 글
| FPN 개념 및 코드 사용 (1) | 2024.01.11 |
|---|



