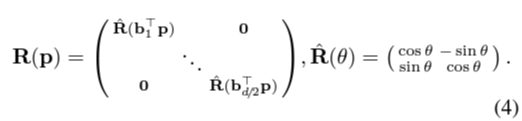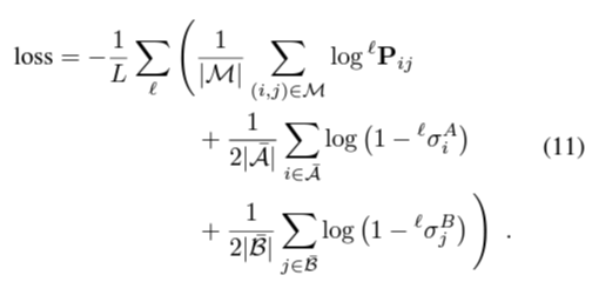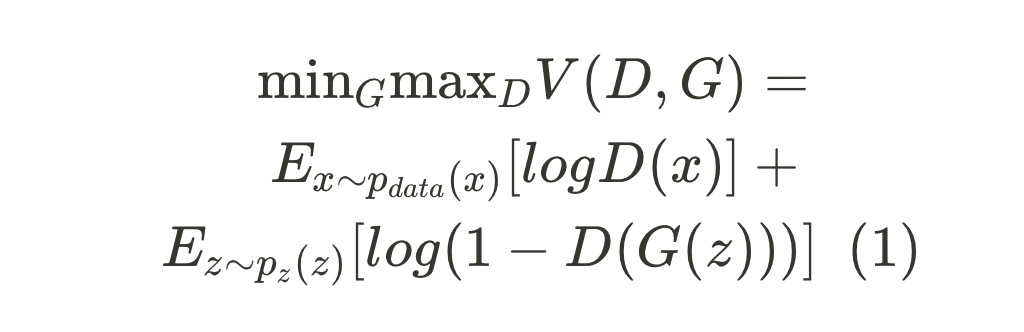본 논문을 읽고 요약한 내용이며 잘못 해석한 내용이 있을 수 있습니다. 설명에 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
1. Motivation
전체 BEV scene level에서 fusion을 진행하는 것은 foreground instance와 배경 사이의 내재적인 차이점을 무시하고 이는 성능을 저하시킴.
3DOD를 위한 BEV 기반의 기존 다중 모달 융합 기법이 가지는 한계를 극복하기 위해, 인스턴스-장면 협업 융합(Instance-Scene Collaborative Fusion) 개념을 제안. 기존 방식이 장면 수준의 융합(Scene-Level Fusion)만을 고려하는 데 반해, 본 연구에서는 개별 객체(인스턴스) 수준에서도 다중 모달 데이터를 활용하여 3D 객체 탐지 성능을 향상하는 방법을 제안. => 작은 객체를 잘 탐지할 수 있음.
기존 BEV 기반 다중 모달 융합 방식이 놓치고 있던 인스턴스 수준의 정보를 명시적으로 통합하여 새로운 Instance-Guided Fusion (IGF) 및 Hierarchical Scene Fusion (HSF) 모듈을 제안.
객체 중심의 탐지 성능 개선
nuScnese 데이터셋에서 최고 성능 달성.
2. Methodology
Fig 2. Overview of our IS-Fusion framework
전체 과정
Multimodal Input Encoding: 각 scene은 LiDAR point cloud P와 LiDAR 센서와 잘 캘리브레이트된 N 개의 카메라로 캡처된 RGB 이미지로 표현됨. PointCloud는 VoxelNet, image는 SwinTransformer를 사용해 객체화함. (Voxel Encoder, Image Encoder)
Multimodal Encoder: multimodal encoder는 앞에서 얻은 두 개의 feature를 cross-modality feature fusion을 수행해 융합된 BEV feature를 생성함. 기존의 방식과 달리, scene level에서만 fusion을 진행하지 않고 instance-level과 scene-level representation을 만듦.
Multimodal Decoder: multimodal decoder는 BEV representation으로부터 최종 3D detection을 수행하는 부분. decoder는 detr에서와 동일하게 사용. 학습 과정에서 Hungarian algorithm이 적용됨. Focal loss, L1 loss가 classification과 3D bounding box regression에 각각 사용.
2.1. Hierarchical Scene Fusion(HSF) 모듈
Fig 3. Illustration of HSF module.
-> 직관적으로 다양한 feature 세분성은 다양한 수준에서 scene context를 캡처한다. (point 수준에서는 객체의 컴포넌트에 대한 세부적인 특징을 제공하는 반면, grid/region 수준에서의 특징은 더 넓은 장면 구조와 객체 분포를 감지할 수 있는 능력이 있음)
Point-to-Grid Transformer: LiDAR Point Cloud를 grid 수준으로 변환하여 BEV 공간에서 장면의 계층적 특징을 학습.
Grid-to-Region Transformer: 인접한 그리드 간 상호작용을 통해 전체 장면의 글로벌 문맥 정보를 학습. local과 global multimodal scene context를 통합할 수 있도록 함.
2.2. IGF 모듈
Fig 4. Illustration of IGF module.
Instance Candidates Selection: BEV에서 특정 객체의 중심을 찾고(scene feature에 keypoint detection head를 적용), 객체별 특징을 추출 (Centerbased 3d object detection 논문에 따라 selection 수행)
Instance Context Aggregation: 선택된 객체가 주변 환경과 어떻게 연관되는지 학습.
Instance-to-Scene Transformer: 객체 수준 특징을 장면 전체의 BEV 표현과 융합하여 탐지 성능을 향상.
2.3. End-to-End 훈련 과정
nuScenes 데이터셋을 기반으로 모델 학습
다양한 데이터 증강 기법 및 Transformer 기반 구조를 활용하여 탐지 성능 최적화.
3. Dataset
nuScenes
4. Result
Table 1. 3D Object Detection Performance on the nuScenes test set.Table 2. Performance comparison on the nuScenes validation set.
SOTA 달성. But, 속도는 SparseFusion에 비해 느림.
5. Limitation
연산량 증가: 기존의 단순 BEV 기반 융합 기법보다 계산량이 증가하여 실시간 시스템 적용이 어려울 가능성이 있음.
본 논문을 읽고 요약한 내용이며 잘못 해석한 내용이 있을 수 있습니다. 설명에 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
1. Motivation
radar-camera fusion 기반의 3DOD시 모델의 robustness를 높이기 위해 레이더 신호의 네 가지 주요 noise patterns에 주목. - Key-point missing : 레이더 포인트 클라우드에서 중요한 특징점이 사라지는 현상. 레이더 빔의 반사 손실 등으로 인해 발생. - Spurious Points : 원래의 레이더 포인트 클라우드에 추가적으로 잘못된 포인트들이 나타나는 현상. 복잡한 외부 환경, 인위적인 간섭으로 인해 발생. - Random Spurious Points : 원래 레이더 포인트와 무관하게 무작위로 생성된 노이즈 - Related Spurious Points : 기존 레이더 포인트의 위치와 관련되어 나타나는 노이즈 - Point Shifting : 레이더 포인트가 원래 위치에서 벗어나는 현상 => radar signal의 품질을 저하시키고, 궁극적으로 3DOD 성능에 부정적인 영향을 미침. 이 네 가지를 해결하기 위해 3D Gaussian Expansion과 CMCA 제안.
2. Methodology
2.1. 3D Gaussian Expansion
Fig 1. Illustration of the 3D Gaussian Expanding.
RCS랑 속도 값을 파라미터 인코더(Proj)에 입력하여 Deformable kernel Map과 가우시안 커널의 분산(시그마)을 결정. Deformable Kernel map에 따라서 점들이 어느 영역까지 영향을 미칠 것인지 결정. (RCS와 Doppler speed가 높은 레이더 포인트는 더 신뢰할 수 있다고 간주, 이러한 포인트들을 중심으로 가우시안 expansion을 수행하여 주변 영역의 특징을 강화)
Fig 2. Architecture of the Confidence-guided Multi-modal Cross-Attention module.
Aggregation : image와 radar feature를 concat한 후, linear projection을 통해 feature aggregation을 수행.
Confidence-guided Fusion: 카메라 신호의 신뢰도를 활용하여 특징을 적응적으로 융합. 카메라 신뢰도가 높을 때는 카메라 특징을 더 많이 반영하고, 레이더 특징은 보조적인 역할만 수행함. 반대의 경우에는 반대로 적용.
Multi-scale Deformable Cross-Attention : Deform cross-attention을 사용해 특징을 융합. 서로 다른 스케일의 특징을 효과적으로 융합할 수 있으며, spatial misalignment를 보정하는 데 유용함. 최종적으로 기존 특징 융합 결과와 confidence-aware feature 융합 결과에 대해 summation 및 convolution 연산을 수행하여 최종 BEV feature를 생성.
=> 다른 것들은 각각 BEV feature를 만들고 fusion을 진행했는데 여기서는 feature를 뽑은 다음에 서로 연관시켜서 하나의 BEV feature를 만듦.
레이더 카메라 기반 방법의 검출 정확도는 주로 카메라에서 나옴. 카메라 신호의 신뢰도가 높을 때 카메라 신호에 더욱 의존, 레이더 신호는 적응형 지원 역할을 함.
3. Dataset
nuScenes + nuScenes에 레이더와 카메라 손상이 있는 노이즈가 있는 데이터를 시뮬레이션해서 사용.
C1~C4는 Spurious Point, Non-positional Disturbance, Key-point Missing, Point Shifting을 의미함.
4. Result
Table 1. 3D Object Detection on nuScenes val set.
더 좋은 성능을 나타내고, 주요하게 제기했던 문제점들에 대해서도 더 좋은 성능을 보여줌. 카메라 기반 3DOD에서는 좋은 성능을 나타내지만 LiDAR와 비교했을 때는 아직 성능이 현저히 낮음.
특히 동시 레이다 신호와 카메라 신호의 간섭이 있는 상태에서 NDS에서 19.4%, 평균 정확도에서 25.7% 향상된 성과를 보임.
5. Conclusion and Limitation
기존의 방식과 달리 3D 가우시안을 사용하여 radar feature를 정제함. CMCA 모듈을 제안하여 카메라 신호의 신뢰도를 활용해 특징적으로 feature를 융합하는 모듈을 제안함. 자율주행에서 어려움을 겪는 요소를 분석하고 그에 따른 데이터셋을 추가하여 학습을 진행함. 카메라 기반 3DOD 태스크에서 SOTA를 달성함. But, LiDAR-camera 멀티모달 모델에 비해 성능이 여전히 낮음. fusion에서 단순한 concatㄹ을 사용함. 3D 복셀화에서 연산량을 따로 고려하지 않음. 데이터 합성의 적절성 등.
본 논문을 읽고 요약한 내용이며 잘못 해석한 내용이 있을 수 있습니다. 설명에 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
1. Motivation
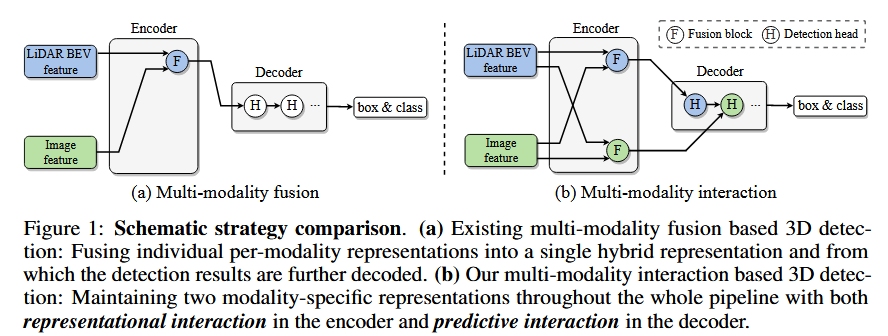
기존 3D object detection 연구들은 multi-modal fusion 전략에 의존함. 그러나 이러한 방식은 modality-specific한 정보들을 간과하기 때문에 결과적으로 성능에 방해가 됨. 따라서 본 논문에서는 개별적인 모달리티별 표현을 학습하고 object detection 과정 동안 고유한 특성을 유지할 수 있도록하는 modality interaction 전략을 새롭게 제안함.
본 논문의 기여는 아래와 같음.
- multi-modal 3D object detection을 위한 새로운 modality interaction 전략을 제안. 기존 전략이 개별 모달리티의 고유한 perception 능력을 저하시키는 한계점을 풀고자 함.
- 이를 해결하기 위해 DeepInteraction 구조를 제안. multimodal representational interaction encoder와 multimodal predictive interaction decoder 구조로 이루어짐.
두 모달리티 간 특징을 교환하는 단계. 이를 위해 cross-modal mapping과 sampling을 수행한 후, attention 기반의 특징 교환을 적용.
- cross-modal mapping & sampling
크로스 모달 매핑은 2D 이미지 공간과 3D LiDAR BEV 공간 사이에서 각 픽셀의 위치 대응을 정의하는 과정. 각 모달리티의 좌표계를 변환하여 상호 연관된 영역을 매핑 2 (a)는 image -> LiDAR BEV로 상호작용, 2 (b)는 LiDAR BEV -> 이미지로 상호작용 . 이를 통해 두 모달리티 간 특징을 정렬하고, 2D 이미지 정보와 3D point cloud 정보를 연결.
image -> LiDAR : 먼저 3D point cloud의 각 좌표를 multi-camera 이미지에 투영해서 sparse depth map을 만들고 depth completion을 통해서 dense depth map을 만듦. 또한 이미지를 3D로 역투영하기 위해서 이 dense depth map을 사용. (파란색이 LiDAR, 초록색이 이미지)
LiDAR -> image : BEV 좌표에서 pillar corresponding을 사용해서 LiDAR point를 얻음. 3D point를 camera intrinsic과 extrinsic에 따라 카메라 이미지 프레임 좌표인 (i,j)에 투영.
- attention-based feature interaction
q : 이미지 모달리티에서 선택된 특징 값 (현재 고려하는 픽셀의 이미지 특징 값) h^c는 이미지 특징 맵. N_q는 쿼리 q에 대응하는 cross modal neighbors 집합. 즉 이미지 픽셀이 LiDAR BEV 공간에서 대응하는 좌표들의 집합. k,v는 모두 N_q에서 가져옴. (쿼리 q가 속한 모달리티와 다른 모달리티) 어텐션 연산을 사용해서 이미지 특징을 LiDAR BEV 특징과 상호작용하여 정제하는 과정. => 단순히 두 모달리티를 “합치는” 것이 아니라, 어떤 LiDAR 정보가 이미지의 특정 픽셀에 가장 중요한지를 어텐션을 통해 학습하는 방식. => 어텐션을 사용하여, 각 모달리티의 중요한 정보만을 선태적으로 교환
(2) Intra-model representational learning (IML)
동시에 멀티모달 상호작용을 보완하는 intra-model representation learning을 수행. 여기서도 (1)이랑 동일한 local attention이 적용됨. 즉, LiDAR BEV는 LiDAR BEV끼리, 이미지는 이미지끼리 학습하면서 정보를 보강 (self-attention 느낌)
(3) Representational integration
두 모달리티 간 정제된 표현을 결합
2. Decoder : Multi-modal Predictive Interaction 객체 탐지(prediction)을 위한 다중 모달 상호작용을 수행하는 부분. => 3 (a)처럼 다른 모달리티를 이용해서 한 모달리티의 3DOD 능력을 향상시키는 것. DETR과 비슷하게 3DOD 문제를 집합 예측 문제로 설정.
Multi-modal Predictive Interaction (MMPI) 각 디코딩 단계에서 이전 층의 예측값을 기반으로 다음 단계를 업데이트. 1) 객체 후보(3D bounding box) 기반 RoI 특징 추출 2) 어텐션 기반의 모달리티 간 상호작용 3) Bounding Box 및 분류 (Classification) 업데이트
l번째 decoding layer에서 set prediction은 이전 레이어의 객체 쿼리와 bounding box prediction을 가져와 계산됨 (상호작용을 가능하게 하기 위해서)
(1) Multi-modal predictive interaction on image representation (MMPI-image)
3D 객체 후보를 2D 이미지에서 RoIAlign을 사용하여 특징을 추출한 후 예측을 보강.
3D bounding box proposal과 객체 쿼리를 디코더의 이전 레이어에서 받아옴.
이미지 모달리티에서 RoI 특징 추출 (R_n은 이 때 n번째 쿼리에서 추출된 feature로 S xSxC의 크기를 지님)
객체 쿼리를 통해 RoI특징을 보강 (1x1 convolution)
(2) Multi-modal predictive interaction on LiDAR representation (MMPI-LiDAR)
위와 비슷하게 디자인됨. LiDAR 표현을 위한 RoI와 관련하여 이전 레이어의 3D 바운딩 박스를 LiDAR BEV 표현 h′p에 투영하고 최소 축 정렬 직사각형을 취함. (자율주행에서 object scale이 일반적으로 작아서 3D bounding box를 두 배로 확대한다고 함) RoI feature의 크기는 MMPI-Image에서와 같음. (C는 channel)
기존의 방식과 다르게 두 모달리티의 표현을 그대로 유지하면서 학습하여 고유한 특성을 살리고자 노력한 접근법이다. 그러나 두 모달리티 표현을 그대로 학습하면서, 교환하며 정보를 학습하기 위해 각각 fusion을 진행하다보니 당연하게도 속도는 느리게 나타났다. (어텐션 연산만 바꿔도 효율성은 높일 수 있을 것 같다)
두 모달리티의 특징을 정말 잘 활용했다고 할 수 있는가? (단순히 어텐션 연산을 사용했다는 것만으로)
본 논문을 읽고 요약한 내용이며 잘못 해석한 내용이 있을 수 있습니다. 설명에 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
1. Motivation
efficiently and accurately match local features across images. It builds upon SuperGlue, improving its efficiency in terms of memory and computation, and enhancing its accuracy and training ease. LightGlue is especially effective in scenarios where rapid matching is essential, like 3D reconstruction. The key innovation of LightGlue lies in its adaptability to the complexity of image pairs, enabling faster inference for easier matches.
2. Methodology
Figure 1. The LightGlue architecture.
Problem formulation
LightGlue는 SuperGlue에 따라 image A와 B로부터 추출된 local feature sets에서 partial assignment를 예측하는 것을 목표로 한다. 각 local feature i는 2D point position으로 구성되어있고, image size, visual descriptor에 따라 normalized된다. a와 b는 각각 M와 N개의 local features를 가지며 인덱스 집합을 A = [1, …, M], B = [1, …, N]으로 나타낸다. 최종 목표는 local features로 구성된 두 집합에 대해 Partial (soft) assignment P를 추론하는 neural network를 디자인하는 것이다.
Overview
전체적인 구조는 Figure 1과 같다. LightGlue는 두 개의 set을 공동으로 처리하는 L개의 identical layer로 이루어져있다. 각 layer는 각 point의 representation을 업데이트하는 self-, cross- attention unit으로 구성되어있다. classifier는 불필요한 계산을 방지하기 위해 각 레이어에서 inference를 중단할 것인지를 결정한다. lightweight head는 최종적으로 set of representations로부터 partial assignment를 계산한다.
2.1. Transformer backbone \(I \in \{A, B\}, x_i^I \in R^d\). state는 대응되는 visual descriptor \(x_i^I <- d_i^I\)로 초기화되고 각 레이어에서 업데이트된다. 여기서 레이어는 하나의 self-attention과 하나의 cross-attention 단위의 연속으로 정의한다.
Attention unit attention unit은 입력된 특징들 사이의 상호작용을 모델링한다. 각 점(데이터의 한 부분)은 다른 모든 점들과의 관계를 계산하여, 어떤 점들이 더 중요한지를 결정한다. 각 unit에서 MLP는 source image \(S \in \{A, B\}\)에서 집계된 message miI S에 따라 상태를 업데이트한다. $$x_i^{I <- S} <- x_i^{I <- S}+MLP([x_i^I| m_i^{I<- S}]) , (1) $$ 여기서 \([ \cdot | \cdot]\)는 두 벡터를 stack하는 것을 의미한다. 이는 두 이미지의 모든 점에 대해 병렬로 계산된다. self-attention unit에서는 동일한 이미지의 지점에서 정보를 가져오기 때문에 S=I이다. 반대로 cross-attention unit에서는 다른 이미지의 지점에서 정보를 가져온다. message는 attention mechanism에 따라 image S의 모든 상태 j의 가중치 평균으로 계산된다. $$m_i^{I<- S} = \sum_{j \in S} \text{Softmax}_{k \in S} (a_{ik}^{IS})_j W x_j^S, (2)$$ 여기서 W는 projection matrix, \(a_{ik}^{IS}\)는 I와 S의 i, j point 사이의 attention score를 의미한다.
Self-attention self-attention은 동일한 이미지 내의 점들 사이의 관계를 학습한다. 즉, 하나의 이미지 내에서 각 점이 다른 모든 점들과 어떻게 관련되는지를 학습한다. 먼저 각 point i에 대해 현재 상태 xi가 key, query vector로 재구성된다. i와 j 사이의 attention score는 아래와 같이 정의된다. $$a_{ij}=q_i^TR(p_j-p_i)k_j, (3) $$
\(R(\cdot) \inR^{dxd}\)는 point 사이의 relative position의 rotary encoding을 의미한다. 주어진 공간을 d/2개의 2차원 subspace로 나눈다. 각 subspace는 Fourier Features에 따라 learned basis \(b_k \in R^2\)에 대한 투영에 해당하는 각도로 회전한다.
rotary encoding은 모델이 점 i로부터 학습된 상대적 위치에 있는 점 j를 검색(retrieve)할 수 있게 해준다. 위치 인코딩은 값 \(v_j\)에 적용되지 않으므로 상태 \(x_i\)로 전달되지 않는다. 이 인코딩은 모든 계층에 대해 동일하며, 따라서 한 번 계산되고 캐시된다.
Cross-attention query없이 각 요소에 대해 key \(k_i\)를 계산한다. $$a_{ij}^{IS}=k_{i}^{IT}k_j^S!=a_{ji}^{SI} . (5)$$ 이 과정은 O(NMd)의 복잡도를 가지기 때문에 이러한 bidirectional attention 방식이 효과적이다. (절반으로 계산량을 감소시키는효과). 이미지 사이의 상대적 위치는 효과적이지 않기 때문에 어떠한 positional information도 더하지 않는다.
2.2. Correspondence prediction Assignment scores 먼저 두 이미지 사이의 score matrix \(S \in R^{M X N}\)을 계산한다. $$S_{ij}= \text{Linear}(x_i^A)^T\text{Linear}(x_j^B), \all (i, j) \in A X B, (6)$$ Linear\((\cdot)\)는 learned linear transformation with bias를 의미한다. 또한 각 point에서 matchability score를 아래의 식으로 계산한다. $$\sigma_i = \text{Sigmoid}(\text{Linear}(x_i)) \in [0, 1], (7)$$
위의 점수는 i가 corresponding point를 가질 가능성을 인코딩한다. 다른 이미지에서 감지되지 않는 점은 매칭될 수 없고 따라서 위의 점수가 0에 가까워진다.
Correspondences similarity와 matchability score를 통합하여 soft partial assignment matrix P를 다음과 같이 구할 수 있다. $$P_{ij} = \sigma_i^A \sigma_j^B \text{Softmax}_{k \in A}(S_{kj})_i \text{Softmax}_{k \in B}(S_{ik})_j. (8)$$ 두 포인트가 matchable할 것으로 예측되고 이미지 사이에서 다른 지점들보다 높은 유사도를 가지고 있을 때 한 쌍의 점 (i,j)는 대응을 생성한다. 저자들은 \(P_{ij}\)가 threshold보다 크고 다른 행과 열에 있는 요소들보다 클 때 pair를 선택한다.
2.3. Adaptive depth and width 불필요한 연산을 줄이고 inference time을 줄이기 위해 두 가지 방식을 사용한다. i) reduce the number of layers depending on the difficulty of the input image pair; ii) prune out points that are confidently rejected early.
Confidence classifier
LightGlue의 backbone은 context를 이용해 input visual descriptor를 강화한다. 만약 두 이미지가 많이 overlapping되어 있고 appearance change가 적다면 early layer에서 만족하고 나머지 layer는 결과가 동일할 것이다. (이미 앞쪽에서 매칭을 완수했으면, 같은 과정을 여러번 거쳐도 결과가 변하지 않음) 따라서 각 layer의 마지막 부분에서 LightGlue는 각 point의 예측된 assignment의 confidence를 추론한다.
값이 큰 것은 i의 representation이 reliable하고 최종적임을 의미한다. compact MLP를 더하는 것은 대부분의 경우에서 시간을 절약할 수 있으며 worst case의 경우에도 inference time을 오직 2% 증가시킨다.
Exit criterion
위의 exit 식이 일정 비율을 만족하면 inference를 종료한다. 초기 레이어에서 confident가 떨어지기 때문에 각 classifier의 validation accuracy에 근거하여 decay한다. exit threshold 는 accuracy와 inference time의 trade-off를 조정한다.
Figure 2. Point pruning. As LightGlue aggregates context, it can find out early that some points are unmatchable and thus exclude them from subsequent layers. Other, non-repeatable points are excluded in later layers. This reduces the inference time and the search space to ultimately find good matches fast.
Point Pruning exit criterion을 만족하지 않는 것은 점들이 confident하고 unmatchable하게 예측됨을 의미한다. 따라서 각 레이어에서 이러한 점들을 제거하고 남은 점들만 다시 일련의 과정을 수행한다. 2차 복잡도로 주어진 attention 연산을 줄일 수 있으며 accuracy에 큰 영향을 주지 않는다.
2.4. Supervision LightGlue를 두 단계로 훈련한다. 먼저, correspondence를 예측하도록 학습하고 그 후에 confidnece classifier를 학습한다. 후자는 최종 레이어나 convergence of training에 영향을 주지 않는다.
Correspondence homography 또는 pixel-wise depth와 상대적 포즈가 주어졌을때, A의 점들을 B로, 그리고 그 반대로 매핑한다. Ground truth matches M은 두 이미지에서 낮은 projection error와 일관된 depth를 가진 점들의 쌍이다. 일부 점들 \( \bar{A} \in A \) 와 \( \bar{B} \in B\)는 그들의 reprojection 또는 depth error가 충분히 클 때 매칭 불가능한 것으로 라벨링된다. 그런 다음 각 레이어 l에서 예측된 assignment의 log-likelihood를 최소화하여 LightGlue가 정확한 대응 관계를 조기에 예측하도록 한다.
첫번째 항은 모델이 대응점을 예측할 때, 실제로 대응되는 점들에 대해 얼마나 잘 예측하는지를 측정한다. 두번째 항은 이미지 A에서 매치될 수 없는 점들에 대한 예측을 측정한다. 세번째 항은 이미지 B에 대해서 같은 작업을 수행한다. 실제로 대응되는 점들을 정확히 예측하면서도, 대응되지 않는 점들을 정확히 식별할 수 있도록 설계되었다. 이러한 방식으로 모델은 정확한 correspondence를 찾고, 오류를 최소화하도록 학습된다.
Confidence classifier Eq (9)의 MLP를 학습시켜 각 레이어의 예측이 최종과 동일한지를 예측한다. \(l m_i^A \in B \cup {\cdot} \)을 layer l에서 B에 있는 점에 대응되는 i의 인덱스로 정의한다. 만약 i가 매칭 불가능하다면 \(l m_i^A= \cdot \) 이다. 각 점의 ground truth binary label은 \([l m_i^A = L m_i^A]\) 이며 B에 대해서도 동일하다. 그런 다음, 레이어의 classifier에 대한 binary cross-entropy를 최소화한다. ( cf. binary cross-entropy는 실제 라벨과 모델이 예측한 라벨 사이의 정보 불일치를 측정. 이 값이 작을수록 모델의 예측이 실제 라벨에 가깝다는 것을 의미함.)
2.5. Comparsion with SuperGlue SuperGlue는 absolute point position을 인코딩하고 descriptor의 앞 단에 이 부분을 fused한다. layer를 통과하면서 positional information을 잊어버리는 경향이 있다는 것을 관측하였다. 따라서 LightGlue는 각 self-attention unit에 relative encoding을 더하였다. SuperGlue는 Sinkhorn 알고리즘을 이용하여 assignment를 계산한다. 이는 많은 iteration이 필요하다. 또한 dubstin 대신 유사도를 사용하여 예측을 효율적으로 하였다. Sinkhorn의 계산량 때문에 SuperGlue는 각 레이어 이후에 예측을 할 수 없고 마지막에서만 예측이 사용되었다. 반면, LightGlue는 각 레이어에서 assignment를 예측하는 것이 가능하고 supervise할 수 있다. 따라서 convergence 속도를 높이고 몇 개의 레이어 이후에 exiting 하는 것이 가능해졌다.
3. Dataset
fine-tuned with MegaDepth dataset test : HPatches(homography estimation), MegaDepth(relative pose estimation), Aachen Day-Night benchmark(visual localization).
4. Result
4.1. Homography estimation SuperGlue를 따라 reprojection error 3픽셀에서 정밀도와 재현율을 비교하였다. 또한 robust하고 non-robust한 solver를 사용하여 homograpy accuracy를 계산하였다. 각 이미지 쌍에 대해, 4개의 이미지 코너의 평균 재사영 오류를 계산하고 AUC 아래 영역을 1픽셀과 5픽셀 값까지 비교하였다. 모든 이미지를 smaller dimension이 480 pixel이 되도록 조정하고, SuperPoint로 1024 local feature 추출하여 matcher를 비교하였다. 공정한 비교를 위해 dense matcher LoFTR, MatchFormer, ASpanFormer의 경우에도 top 1024개의 결과를 사용해 비교하였다.
Table 1. Homography estimation on HPatches.
P는 precision, R은 recall을 의미한다. SuperGlue, SGMNet과 유사한 recall 값을 가지면서 더 높은 precision을 갖는 것을 볼 수 있다. LightGlue는 LoFTR과 같은 dense matcher에 비해 더 좋은 성능을 보인다. coarse threshold 5px에서 sparse keypoint의 제약이 있음에도 불구하고 LoFTR보다 더 정확하다.
4.2. Relative pose estimation strong occlusion과 challenging lighting 및 구조적 변화를 보이는 outdoor scene에서 성능을 평가하였다. MegaDepth-1500 dataset로 평가를 진행하였다. (테스트 세트에는 two popular phototourism destinations: St. Peters Square and Reichstag의 1500개의 이미지가 포함된다.) vanilla RANSAN과 LO-RANSAC을 사용하여 essential matrix를 추정하고 이를 rotation과 translation으로 분해한다. inlier 임계값은 테스트 데이터에 대해 각 접근 방식에 맞게 조정된다. 각 이미지에서 2048개의 local feature를 추출하고 1600 pixel의 larger dimension을 가지도록 resize한다. dense deep matcher의 경우 그들의 largest dimension을 840 pixel (LoFTR, MatchFormer) 또는 1152 pixel (ASpanFormer)로 resize한다. 더 큰 이미지는 accuracy를 향상시키지만, runtime과 memory 측면에서 허용할 수 없는 정도이기 때문에 dense matcher의 사이즈를 위와 같이 조정하였다.
Table 2. Relative pose estimation
Table 2는 LightGlue가 기존 접근법을 능가함을 보여준다. 더 나은 대응점과 더 정확한 relative pose estimation을 제공하고 inference time을 30% 정도 줄인다.
4.3. Outdoor visual localization
Table 3. Outdoor visual localization
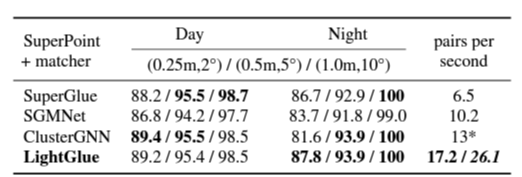
대규모 Aachen Day-Night benchmark를 사용하여 challenging condition에서 long-term visual localization을 평가하였다. 저자들은 hloc toolbox와 Hierarchical Localization framework를 따른다. 먼저 4328개의 daytime reference image로부터 알려진 포즈와 보정을 사용하여 sparse 3D point cloud를 COLMAP을 사용해 삼각측량한다. 824개의 daytime과 98 night time 쿼리에 대해 NetVLAD와 50개의 이미지를 검색하여 각각을 매칭하고 카메라 포즈를 추정한다. RANSAC과 Perspective-n-Point solver를 사용한다. 다양한 임계값에서 포즈 재현율을 보고하고 매핑과 위치 결정동안의 매칭 단계에서 평균 정확도를 보고하였다. SuperPoint를 사용해 4096개의 feature를 추출하고 각 matcher로 매칭을 진행하였다. LightGlue는 SuperGlue와 유사한 정확도를 가지면서 2.5배 많은 throughput을 만든다.
4.4. Insights Ablation study
SuperGlue와 비교할 때, LightGlue는 훨씬 빠르게 수렴하며 +4%의 재현율과 +12%의 정밀도를 달성한다. matchability classifier가 없을 때, 네트워크는 좋고 나쁜 매치를 구분하는 능력을 잃게 된다. 유사성 행렬은 많은 가능성 있는 매치를 제안하는 반면, 매칭 가능성 필터는 부정확한 제안들을 걸러낸다. 따라서 partial assignment는 상호 가장 가까운 이웃과 학습된 inlier 분류기의 elegant fusion으로 볼 수 있다. 이는 SuperGlue의 optimal transport problem보다 훨씬 빠르다.
학습된 absolute positional encoding을 상대적 위치 인코딩으로 대체함으로써 정확도가 향상되고, minor penalty로 인한 쿼리와 키의 각 셀프 어텐션 레이어를 개선한다. relative position을 사용하여 LightGlue는 이미지 간의 기하학적 패턴을 학습하여 매치한다. 이는 각 레이어의 위치에 대해 상기시키는 것은 정확도를 개선한다.
Bidirectional cross-attention은 standard cross attention과 동일한 정확도를 가져오면서 20%의 runtime 감소효과가 있다. 현재 bottleneck은 두 차원을 따라 softmax를 계산하는 것에 있다.
deep supervision을 사용하는 것은 또한 중간 레이어가 의미있는 결과를를가지도록 한다. 5 레이어만 지났을 때에도 모델은 90%가 넘는 recall을 얻는다. 마지막 레이어에서 네트워크는 outlier를 제거하는 데 집중하여 match precision을 개선할 수 있다.
Adaptivity
비디오의 연속된 프레임들 같은 경우 네트워크는 빠르게 수렴하고 몇 개의 레이어 후에 빠져나와 1.86배의 속도를 향상시킨다. visual overlap이 낮은 경우, 예를 들어 loop closure의 경우 네트워크가 수렴하기 위해 더 많은 레이어가 요구된다.
Efficiency Figure 7은 input keypoint의 개수에 따른 run time을 보여준다. visual localization의 흔한 세팅인 2k keypoint에서 LightGlue는 다른 네트워크를 능가하는 결과를 보여준다.
5. Conclusion & Limitation
이 논문은 이미지 전반에 걸쳐 sparse local feature들을 매칭하기 위해 훈련된 deep neural network인 LightGlue를 소개한다. 제안된 모델은 자체 예측에 대한 확신을 내부적으로 파악하는 능력을 부여한다. 모든 예측이 준비되면 초기 레이어에서 inference를 멈출 수 있고, 매칭되지 않는 것으로 판단된 포인트들은 초기 단계에서 더 이상의 단계를 거치지 않고 버려진다. 제안된 모델은 더 빠르면서 정확하며 훈련하기 쉽다.
*) Rotary Positional Embeddings : Additive form이 아닌 Multiplicative 기법 + Sinusoid 아이디어를 활용한 방법. 통합적인 Relative Position Information을 위하여 Query, Key의 inner product, 함수 g로 정의된 position encoding을 찾고 싶고, g는 Word Embeddings과 상대적인 Position m-n만을 input으로 가질 수 있도록 정의하고자 하는 것이 목적이다. 2D plane의 Geometric property를 사용한다. 원래 벡터에 회전을 적용하여 위치정보가 인코딩된 상태로 표현한다.
*) Fourier Features Positional Encoding In the context of the learnable Fourier features, instead of having fixed frequencies and amplitudes like in the traditional method, you would have learnable parameters. Let’s represent these parameters as:
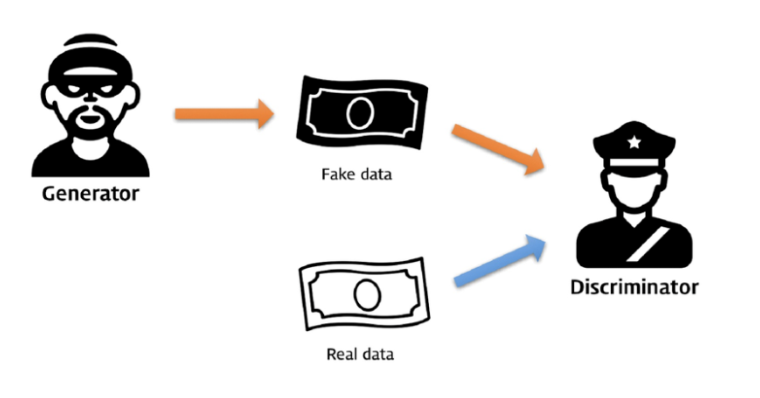
- 비지도학습에 사용되는 머신러닝 프레임워크의 한 종류. - 생성모델(generator) : 최대한 진짜 같은 데이터를 만들기 위한 학습을 진행 - 분류모델(discriminator) : 진짜와 가짜를 판별하기 위한 학습을 진행 - GAN의 학습 과정에서는 분류 모델을 먼저 학습시키고, 생성모델을 학습시킴. - 분류모델은 먼저 진짜 데이터를 진짜로 분류하도록 학습. - 다음으로 생성모델이 생성한 데이터를 가짜로 분류하도록 학습. - 마지막으로 학습된 분류모델을 속이는 방향으로 생성모델을 학습시킴
# Introduction
- 딥러닝이 작동하는 방식은 인공지능 영역에서 마주하는 데이터의 종류에 대해서 모집단에 근사하는 확률 분포를 나타내는 계층모델을 발견하는 것. 지금까지 고차원의 방대한 센싱 데이터를 클래스 레이블에 매핑하여 구분하는 모델 사용 - well-behaved gradient를 갖는 선형 활성화 함수들을 사용한 backpropagation, dropout 알고리즘 기반 - Deep generative model들은 많은 확률 연산들을 근사하는데 발생하는 어려움과 generative context의 선형 활성화 함수의 이점을 가져오는데 어려움이 있어 크게 임팩트있지 않았음.
- 제안하는 adversarial nets framework는 이러한 어려움을 회피하는 경쟁적 모델. G는 진짜 같은 데이터를 생성하고, D는 진짜와 가짜를 구별할 수 있도록 학습됨. 경쟁적으로 학습되면서 더 진짜같은 데이터를 생성할 수 있도록 함. - 이러한 framework는 다양한 종류의 모델 및 최적화 알고리즘에 대한 특정 training 알고리즘을 생성할 수 있음. - D, G는 꼭 neural network로 만들 필요가 없음. 어떤 모델이든 적대적인 역할을 잘 해줄 수 있다면 상관없음.
# Adversarial nets
- adversarial modeling framework는 모델이 둘다 multilayer perceptron일 때, 가장 직관적으로 적용될 수 있음.
- G는 log(1-D(G(z))를 최소화 (D(G(z))를 최대화)하기 위해 학습되고, D는 training data와 G의 sample에 올바른 라벨을 지정한 확률을 최대화하기 위해 학습됨. - D는 V(D, G)를 최대화시키려고하고, G는 V(D, G)를 최소화하려고 하기 때문에 논문에는 value function V(D, G)를 갖는 two-player minmax game으로 표현.
- 학습시킬때 inner loop에서 D를 최적화하는 것은 많은 계산을 필요로하고, 유한한 데이터셋에서는 overfitting을 초래함. - k step만큼 D를 최적화하고 G는 one step만큼 최적화.
- blue : D / black : data generating (real) / green : G, fake - 그림을 보면, 학습초기에는 real과 fake가 다르고, D의 성능이 좋지 않음. - 학습이 진행될수록 real과 fake의 분포가 거의 비슷해지며, D의 확률은 1/2로 수렴.
# Theoretical Results
- GAN의 minmax problem이 제대로 작동한다면, global minimum에서 unique solution을 가지고, 어떠한 조건에 만족하면 그 solution으로 수렴한다는 사실이 증명되어야함. - Global Optimality of $P_g = P_{data}$ - Convergence of Algorithm 1
# Experiments
- MNIST, Toronto Face Database (TFD), CIFAR-10에 대해 학습 진행. - generator는 rectifier linear activation과 sigmoid activation을 혼합하여 사용, discriminator는 maxout activation 사용. - discriminator net을 학습할 때 dropout 적용. - 이론적인 프레임워크에서는 generator의 중간층에 dropout 사용과 다른 noise를 허용하지만, 실험에서는 generator network의 최하위 계층에 input으로 noise 사용. - G로 생성된 sample에 Gaussian Parzen window로 맞추고, 해당 분호에 따른 log-likelihood를 알려줌으로써 test set data 추정. 이때 정규분포의 분산 파라미터는 교차검증을 통해 얻음. 이러한 방식으로 likelihood를 추정하는 것은 다소 분산이 크며, 고차원 데이터 공간상에서 품질이 좋지 못하지만 최선의 방식이어서 이러한 방식을 사용함.
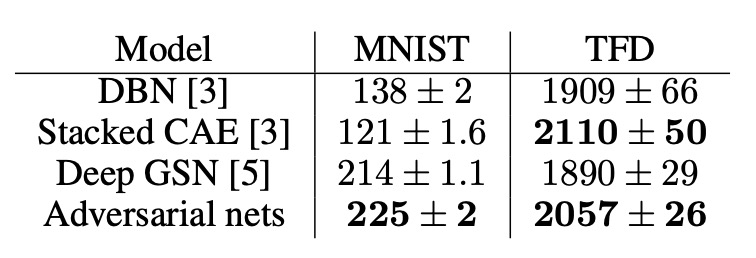
- 기존의 방식들에 비해 경쟁력있는 결과를 보여주며, adversarial framework의 잠재력을 보여줌.
# Advantages and disadvantages
- disadvantage - no explicit representation of $p_g(x)$ - D와 G가 균형을 잘 맞추어야함. - G가 D의 학습없이 너무 많이 학습되어서는 안됨. D의 가중치를 조정하는 과정없이 G만 계속해서 가중치를 조정할 경우, Helvetica scenario에 빠지게 되어 원하는 G를 얻지못함. - advantage - Markov chain이 필요없고, 오직 backprop만 사용. - 학습 중에 inference가 필요하지 않음. - 다양한 함수들이 모델에 접목될 수 있음. - 모델을 만들 때 데이터 예제를 통해 직접적으로 가중치를 업데이트하는 게 아니라 discriminator D를 통한 gradient의 흐름으로만 가중치를 업데이트할 수 있음.
# Conclusions and future work
1. G와 D에 c를 input으로 추가함으로써 conditional generative model로 발전시킬 수 있음. 2. Learned approximate inference는 주어진 x를 예측하여 수행될 수 있음. 3. parameter를 공유하는 conditionals model을 학습함으로써 다른 coditional models를 근사적으로 모델링할 수 있음. 4. semi-supervised learning : 제한된 레이블이 있는 데이터를 사용할 수 있을 때, discriminator 혹은 inference net의 feature로부터 classifier의 성능을 향상시킬 수 있음. 5. Efficiency improvements: G, D를 조정하는 더 나은 방법이나 학습과정에서 sample z에 대한 더 나은 분포를 결정함으로써 학습 속도를 높일 수 있음.
본 논문을 읽고 요약한 내용이며 잘못 해석한 내용이 있을 수 있습니다. 설명에 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
1. Motivation
Figure 1. The main idea of human-friendly topic assisted feature matching, TopicFM.
데이터 마이닝의 topic modeling 전략을 기반으로 이미지에 대한 high-level information을 인코딩한다. TopicFM은 topic에 대한 다항 분포로 이미지를 모델링한다. 여기서 topic은 객체 또는 구조적 형태와 같은 latent semantic instance를 의미한다.
이러한 방식은 semantic 정보를 기반으로 빠르게 covisible 영역을 탐색하고 그 안에서 matching point를 찾는 인간의 지각 시스템과 비슷하다. TopicFM은 이미지에서 같은 semantic area에 집중해 feature를 학습한다. (Figure 1에서 같은 색깔을 가진 영역, 즉 같은 semantic 영역에서만 대응되는 matching을 찾음.) 따라서 이미지의 전체 영역에서 transformer로 feature를 학습하는 기존의 방식에 비해 계산량이 적다.
semantic instance와 같은 high-level context를 효과적으로 활용해 global context를 적절하게 통합하고 계산을 줄이면서 matching performance 성능도 좋은 모델을 제안하였다.
2. Methodology
Figure 2. Overview of the proposed architecture.
전체적인 구조는 Figure 2와 같다. pixel-level accuracy를 유지하면서 real-time에서 고해상도 이미지 매칭이 가능하도록 coarse-to-fine method로 설계하였다. 이미지 매칭은 크게 3가지 단계로 이루어진다. a) feature extraction, b) coarse-level matching, c) fine-level matching. coarse matching 단계에서는 topic-assisted matching module인 TopicFM을 사용하여 매칭 확률 분포를 추정한다. 이후 단계에서 고해상도 feature를 사용하여 더 fine한 수준으로 매칭을 개선한다.
Figure 3. Overview of the LoFTR.
Figure 3은 LoFTR [3]의 전체적인 구조를 나타낸다. TopicFM은 LoFTR의 구조를 baseline으로 하여 runtime과 accuracy를 개선하기 위해 b) coarse-level matching 방식을 수정하였다.
2.1. Topic-Assisted Feature Matching
2.1.1. Probabilistic Feature Matching
주어진 두 feature set {FcA, FcB}에 대해 가능한 모든 매칭 M={mij}의 매칭 분포를 추정하는 것이 목표이다.
P(M | FcA, FCB) = mijMP(mij|FcA, FcB) (1)
여기서 {mij}는 random variable로 Fc,iA의 i번째 feature와 Fc,jB의 j번째 feature가 매칭되는 사건을 의미한다. 기존의 방식들과 달리 TopicFM은 topic의 잠재 분포를 사용하여 매칭 분포를 추정한다.
Eq 1을 풀기 위해, 먼저 각 feature point에 대한 distribution을 추론하고 (Eq. 3), 각 매칭 후보에 대해 topic조건을 부여한 매칭 확률을 추정한다 (Eq. 4). 이때, 이 확률을 계산하기 위해 샘플링 전략이 사용된다 (Eq. 5 and Eq. 6). 마지막으로 확률 임계값을 사용하여 후보 중에서 coarse matches를 선택한다.
2.1.2. Topic Inference via Transformers
Figure 4. Topic Inference
먼저 이미지를 flatten한 후 각 feature point가 어떤 topic에 속하는지를 결정하기 위해 Topic Inference 단계를 거친다. 저자들은 구조적인 모양이나 semantic instance가 특정 데이터셋에서 K개의 topic으로 분류될 수 있다고 가정했다. 따라서 각 이미지는 K개의 주제에 대한 다항 분포로 모델링될 수 있다.
zi와 i는 각 feature에 대한 topic indicator와 topic distribution을 의미한다. 여기서 zi {1, ..., K}, i, k = p(zi=k | F)를 의미한다. topic k는 학습 가능한 임베딩 벡터 Tk로 표현되며 transformer를 사용하여 global representation으로부터 local topic representation Tk를 얻어 확률을 추정한다. 그림에서 Cross-Attention을 하기 전 topic embedding이 Tk, cross-attention을 거친 후의 임베딩 벡터가 Tk이다. local topic representation은 그림과 같이 Tk=CA(Tk,F) (2)를 통해 얻는다. 마지막으로 topic 확률 i, k 는 feature와 각 topic 사이의 거리로 정의한다.
i, k =< Tk, Fi>h=1K< Th,Fi> (3)
2.1.3. Topic-Aware Feature Augmentation
Figure 5. Topic-aware Feature Augmentation
이 단계에서는 매칭된 후보에 대해 Eq. 1을 계산하여 매칭 확률을 추정한다. feature point pair에 대해 정의한 latent variable zij를 계산하기 위해 Eq. 4를 이용한다.
Eq.4 를 계산하기 위해 evidence lower bound(ELBO)를 이용해 Eq.5의 첫번째 식과 같이 근사할 수 있다. 이는 Monte-Carlo (MC) sampling을 적용해 Eq.5 와 같이 추정할 수 있다. 이 샘플링 방식은 가지고 있는 데이터를 이용해 기댓값을 알아내기 위한 방식으로 모든 K topic을 반복해 계산할 필요 없이 아래와 같은 식으로 바로 계산될 수 있어 효율적이다. ( S << K)
그러면 확률을 계산하기 위한 문제는 topic distribution P(zij|FcA,FcB)와 conditional matching distribution P(mij|zij(s),FcA,FcB)의 계산으로 축소된다. topic distribution은 k가 NaN이 아닐때는 FcA,FcB에 대한 i, k A, i, k B의 곱으로 구할 수 있고, NaN인 경우 1에서 k가 1부터 K일때까지 확률의 합을 빼서 구한다. (일련의 단계는 Figure 5의 sample 부분과 같다.)
두 이미지의 topic distribution을 비교하여 covisible topic을 결정한 후, 이 부분에 대해서 feature augmentation을 적용한다. 여기서 feature augmentation은 feature의 고유성을 확장하기 위한 단계로 transformer의 self-attention과 cross-attention을 사용하여 얻는다. 결과적으로 Eq. 6의 zij(s)은 SA, CA를 적용한 feature사이의 distance를 계산하고 이를 dual-softmax로 정규화함으로써 결정된다.
2.2. Efficient Model Design
Backbone으로는 ConvNext를 사용하였다. coarse matching step에서 TopicFM은 single block self/cross attention을 사용하였고, feature를 추출하기 위해 topic간의 정보를 공유하였다. 이러한 연산은 오직 covisible topic에만 적용되기 때문에 multi-block transformer를 사용한 다른 모델에 비해 연산이 효율적이다. 마지막으로 fine matching step에서 LoFTR은 self/cross attention을 모두 사용한 것과 다르게 cross-attention만 사용하여 연산량을 줄였다.
3. Dataset
LoFTR과 동일하게 MegaDepth로 train한다. 평가에는 HPatches, MegaDepth, ScanNet, Visual localization benchmark dataset을 사용하였다.
4. Result
Figure 6. Comparison between proposed model and SOTA Transformer-based methods on the MegaDepth dataset. The runtime and computational cost are measured at the image resolution of 1216 x 1216.
Table 1. Evaluation of relative pose estimation on MegaDepth and ScanNet.
Table 2. Evaluation of visual localization on Aachen Day-Night v1.1.
5. Conclusion and Limitation
성능을 높이는데만 집중했던 기존의 방식과 달리 성능을 높이면서 runtime을 줄이고자 시도하였다. 또한 topic modeling과 인간의 지각 시스템을 모방하여 semantic 정보를 활용하여 매칭될 수 있는 영역을 정한 후, 영역 내에서 매칭하는 방식으로 모델을 설계하였다. real-time semantic segmentation 혹은 real-time object detection의 모델을 활용해 본 논문처럼 매칭 가능 영역을 설정한 후 매칭하는 방식도 활용해 볼 수 있을 것이다.
Table 1과 Table 2를 보면 변화가 클 때 (각도가 클때) 다른 모델에 비해 성능이 떨어진다. TopicFM-fast의 경우 runtime이 56 ms로 측정되었다. 이는 CNN-based인 DGC-Net과 비슷한 결과이다 (55.59 ms). 그러나 하드웨어 친화적이지 않은 연산이 포함되어 있어 하드웨어별로 latency가 다르게 측정될 수 있다.
매칭 단계에서 standard self-attention과 cross-attention이 사용되었다. standard attention 연산의 경우 2차 복잡도를 지니기 때문에 attention 연산만 줄이더라도 runtime이 감소될 수 있다.