본 논문을 읽고 요약한 내용이며 잘못 해석한 내용이 있을 수 있습니다. 설명에 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
요약
1. 연산량을 줄이기 위해 FLOPs나 Parameter 계산을 metric으로 주로 사용하였는데, 이론적인 계산과 실제 처리량과는 차이가 있음. 이를 개선하기 위해 direct metric으로 측정할 것을 제안
2. 이를 바탕으로 Efficient Vision Transformer의 backbone인 LITv2 제안
3. 이미지의 주파수별 특성에서 아이디어를 얻어, head를 Hi-Fi와 Lo-Fi로 분리하여 이미지의 local & global 정보를 효율적으로 캡처할 수 있는 HiLo attention mechanism을 제안함.
4. 기존의 attention mechanism에 비해 더 빠른 속도로 이미지를 처리하면서 경쟁력 있는 정확도를 얻음.
[Abstract]
기존의 Efficient design은 플랫폼과 관계없이 이론적인 계산량인 FLOPs를 가이드로 평가되었다. 그러나 이러한 방식은 실제 처리량과는 분명한 차이점이 존재한다. 본 논문에서는 Efficient ViT를 설계하기 위한 디자인 원칙으로 타깃 플랫폼에서 직접 속도 평가를 측정하는 것을 제안한다. 이러한 metric을 중심으로 다양한 스펙트럼의 모델 크기에서 SOTA를 달성하는 간단하고 효과적인 LITv2를 제안한다.
LITv2의 핵심은 저자가 제안한 HiLo라고 불리는 self-attention mechanism에 있다. HiLo는 높은 주파수는 이미지의 local fine detail을 캡처하고, 낮은 주파수는 전역적인 구조를 캡처하는 것에 insight를 얻어 제안되었다. 따라서, 저자는 head를 두 개의 그룹으로 분리하여 attention layer에서 고/저 주파수 패턴을 분리할 것을 제안한다. 여기서 한 그룹은 각 로컬 창 내에서 self-attention을 통해 고주파를 인코딩하고, 다른 그룹은 average pooling 된 저주파 키와 각 window의 값과 input feature map의 각 쿼리 위치 간에 global attention을 수행하여 저주파를 인코딩한다. 두 그룹의 효율적인 설계를 통해 FLOPs, GPU와 CPU에서의 속도와 메모리 소비량에서 종합적으로 우수함을 보여준다.
[Related Work]
Metric
일반적으로, 최근 ViT 모델의 indirect metric (FLOPs)와 direct metric (speed) 차이의 원인으로는 크게 두 가지 이유가 있다. 첫번째로 self-attention이 low-resolution feature map에서 효율적이지만, 메모리와 시간의 2차 복잡성으로 인해 memory access cost가 많이 들기 때문에 고해상도 이미지에서 속도가 훨씬 느려진다. 두 번째로 ViT의 일부 효율적인 어텐션 메커니즘은 이론적인 복잡성이 낮지만 하드웨어 친화적이지 않거나 병렬화할 수 없는 특정 작업 (multi-scale window partition, recursion, dilaed window)로 인해 GPU에서 실제로 느리다.
Efficient attention mechanisms
Efficient attention mechanism은 standard MSA의 2차 시간 복잡도를 줄이는 것을 목표로 한다. NLP에서의 기존 접근 방식은 low-rank decomposition, kernelization, memory, sparsity mechanism의 카테고리가 있었다. 그러나 단순히 이러한 방식을 채택하는 것은 CV task의 차선책으로 수행된다. CV에서 대표적인 efficient self-attention mechansim은 spatial reduction attention (SRA), local window attention, twins attention 등이 있다. 그러나 이들은 같은 레이어에서 local이나 global 둘 중 하나에만 초점을 맞춘다. 이 문제를 해결하기 위해 TNT는 추가적인 global token을 도입했고, MixFormer는 depthwise convolutional layer와 함께 local window attention을 혼합하였다. Focal 및 QuadTree는 두 가지(local과 global)를 동시에 고려한다. 그러나 하드웨어친화적이지 않고 FLOPs에 반영할 수 없는 비효율적인 작업으로 인해 표준 MSA와 비교해도 GPU에서 느리다.
Frequeny domain analysis in vision
이미지의 저주파는 일반적으로 전체 구조와 색상 정보를 캡처하는 반면, 고주파는 물체의 미세한 세부 사항을 캡처한다. 이러한 insight를 바탕으로, image superresolution, generalization, image scaling, neural network compression을 위한 수많은 솔루션이 제안되었다. 또한, Octave convolution은 convoluional layer를 대상으로 하여 고해상도/저해상도 feature map에 별도로 convolution을 국소적으로 적용하는 것을 제안하였다. 이와 달리 제안된 HiLo는 self-attention으로 local 및 global 관계를 모두 캡처하는 새로운 attention mechanism이다.
[Methodology]
1. HiLo Attention
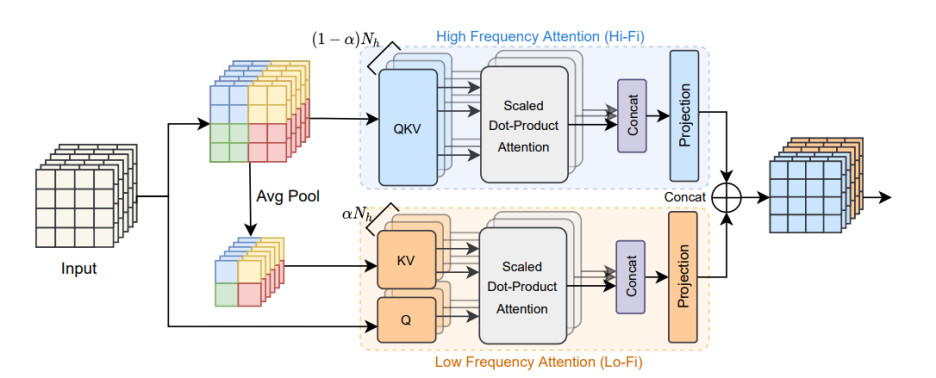
전체적인 HiLo attention mechanism의 구조는 Figure 1과 같다. Lo-Fi에서 이미지의 global한 정보를 Hi-Fi에서 이미지의 local 한 정보를 처리한다.
High-frequency attention
직관적으로 고주파수는 물체의 local detail을 인코딩하므로 feature map에 global attention을 적용하면 중복되고 계산 비용이 많이 든다. 따라서 본 논문에서는 계산 복잡성을 줄이기 위해 local window self attention으로 세분화된 고주파수를 캡처하도록 Hi-Fi를 설계할 것을 제안한다. 또한 본 논문에서는 Hi-Fi에서 간단하고 겹치지 않는 window partition을 사용한다. 이는 window shifting이나 multi-scale window partition와 같은 시간 소모적인 작업에 비해 하드웨어 친화적이다.
Low-frequency attention
최근의 연구들은 MSA의 global attention이 낮은 주파수를 캡처하는 데 도움이 된다는 것을 보여준다. 그러나 MSA를 high-resoultion feature map에 직접 적용하려면 막대한 계산 비용이 필요하다. averaging은 low-pass filter이므로 Lo-Fi는 먼저 각 window에 average pooling을 적용하여 입력값 x에서 저주파 신호를 얻는다. 다음으로 average-pooled feature map이 키 및 갑에 투영된다. Lo-Fi의 쿼리 Q는 여전히 원본 feature map X에서 가져온다. 그런 다음 feature map에서 풍부한 저주파의 정보를 캡처하기 위해 standard attention을 적용한다. K와 V의 공간 감소로 인해 attention과정에서의 계산량이 줄어든다.
Head splitting
가장 naive한 solution은 standard MSA layer와 동일한 수의 head를 Hi-Fi와 Lo-Fi에 할당하는 것이다. 그러나, head를 두 배로 늘리면 더 많은 계산 비용이 발생한다. 더 나은 효율성을 위해 HiLo는 MSA에서 동일한 수의 헤드를 분할 비율을 사용해 두 그룹으로 분리한다. 이러한 방식에서 각 어텐션은 standard MSA보다 복잡성이 낮기 때문에 HiLo의 전체 프레임워크는 낮은 복잡성을 보장하고 GPU에서 높은 처리량을 보장한다. 또한 헤드 분할의 또 다른 이점은 learnable parameter를 두 개의 더 작은 행렬로 분해할 수 있어 모델 매개변수를 줄이는 데 도움이 된다는 것이다. 최종적으로 HiLo의 output은 각 어텐션의 output을 concatenation 하여 얻을 수 있다.
Complexity Analysis

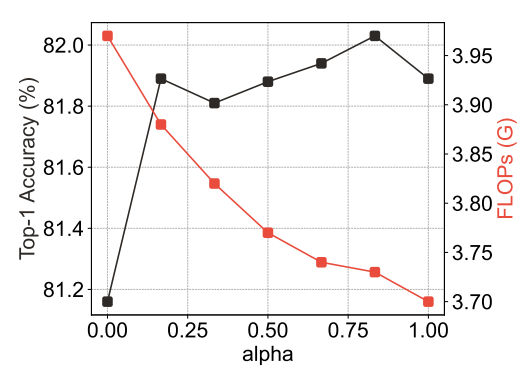
그림 2(a)와 2(b)에서 볼 수 있듯이 작은 입력 이미지 해상도와 작은 s값에서 Hi-Fi와 Lo-Fi 모두 비교적 효율적이다. 그러나 훨씬 더 높은 해상도를 사용하는 Lo-Fi는 여전히 2차 복잡도를 가지므로 막대한 계산 비용이 발생한다. 이 경우, s를 약간 늘리면 Lo-Fi가 정확도를 유지하면서 더 나은 효율성을 달성하는데 도움된다.
2. Positional Encoding
fixed RPE는 이미지 해상도가 다른 경우 보간을 일으키기 때문에 training/inference 속도를 늦출 수 있다.
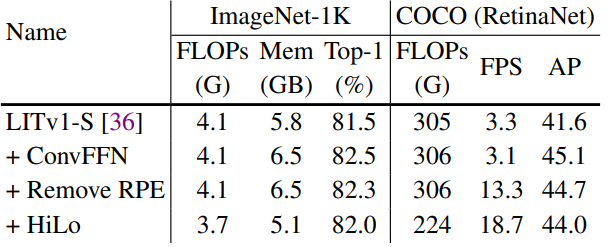
최근 연구에 따르면 위치 정보는 CNN의 zero-padding으로부터 암시적으로 학습된다는 것을 보여주었다. 따라서 시간을 많이 소모하는 RPE를 대체해 각각의 FFN에서 zero-padding이 있는 3 x 3 deptwise convolutional layer의 한 레이어를 채택할 것을 제안한다. 기존의 MSA를 제거했기 때문에 LITv1의 초기 블록에는 FFN만 남아 있어 1 x 1의 receptive field가 생성된다. 이를 위해 section 5.4에서 각 FFN에 채택된 3 x 3 convolutional filter가 초기 단계에서 receptive filed를 동시에 확대하여 LITv2도 개선함을 보여준다.
3. Model Architecture
LITv2는 base setting을 LITv1으로 하여 S, M, B 세 가지 크기로 설계되었다. 공정한 비교를 위해 네트워크의 너비와 깊이는 LITv1과 동일하게 설계하였다. 전반적인 수정은 1) Adding one layer of depthwise convolution with zero-padding in each FFN and removing all relative positional encodings in all MSAs. 2) Replacing all attention layers with the proposed HiLo attention. ( Positional encoding을 제거하고 FFN에 zero-padding depthwise convolution layer를 한 층 추가하고, 기존의 attention을 HiLo attention으로 대체 )
[Result]
* ) Image classification on ImageNet-1K, Object detection and instance segmentation on COCO, Semantic segmentation on ADE20 K.
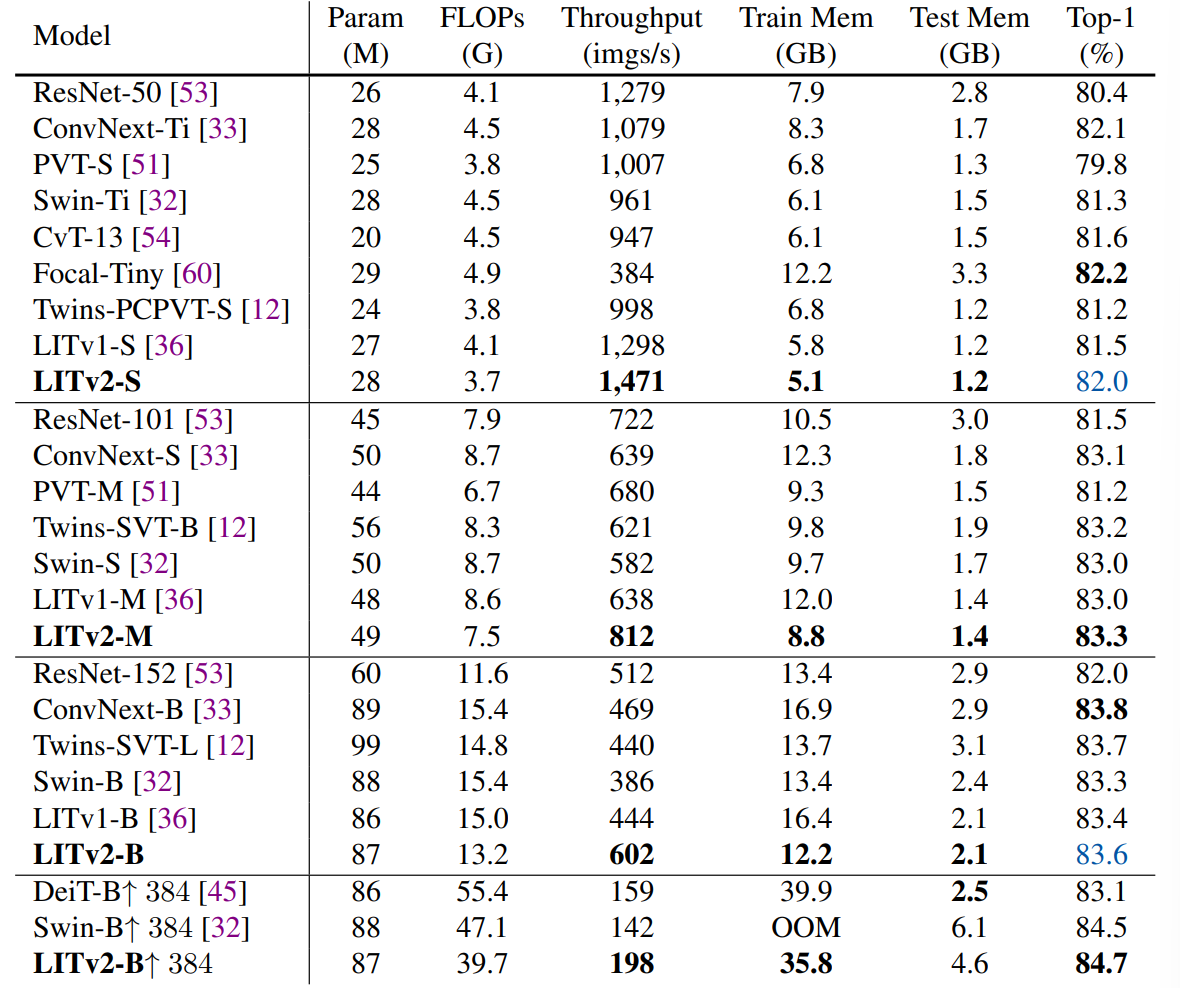
1. Image Classification on ImageNet-1K
본 논문에서는 mobile-level architecture에 대해서는 고려하지 않고 CNN-based model과 여러 가지 SoTA ViT에 대해 평가를 진행했다. 대신, 비슷한 모델 사이즈에서 어떻게 작동하는가에 초점을 맞추어 연구를 진행하였다.
Implementation
: 300 epoch, 8 V100 GPUs, batch size as 1024. input image 224 x 224, learning rate 1 x 10^(-3), weight decay 5 x 10^(-2), AdamW optimizer, window size s 2, split ratio 0.9
Results
2. Object Detection and Instance Segmentation on COCO
Implementation
모든 backbone은 ImageNet-1K에서 pretrain된 weight로 초기화. 8 GPUs with 1x schedule (12 epochs), total batch size 16, window size 2. *로 표시된것은 window size 4 FLOPs는 1280 x 800 해상도를 기준으로 계산되었고, FPS는 RTX 3090 GPU를 기준으로 측정되었다.Results
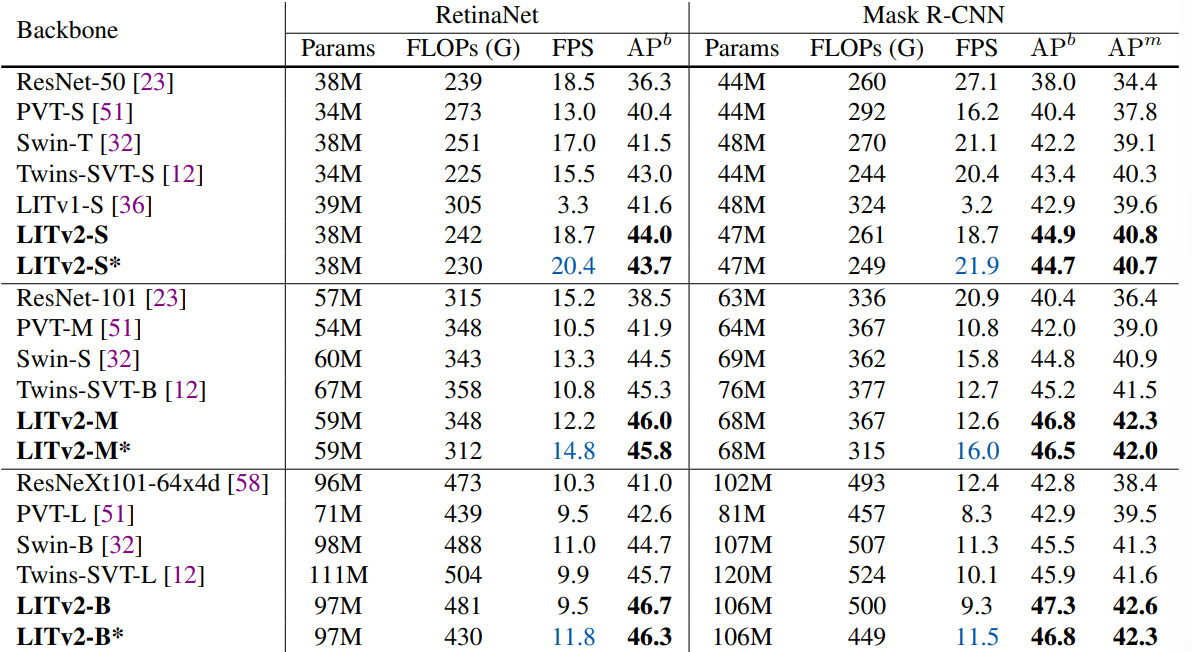
window size를 늘렸을 때 성능이 약간 하락되기는 했으나 더 나은 효율성을 보여준다.
3. Semantic Segmentation on ADE20K
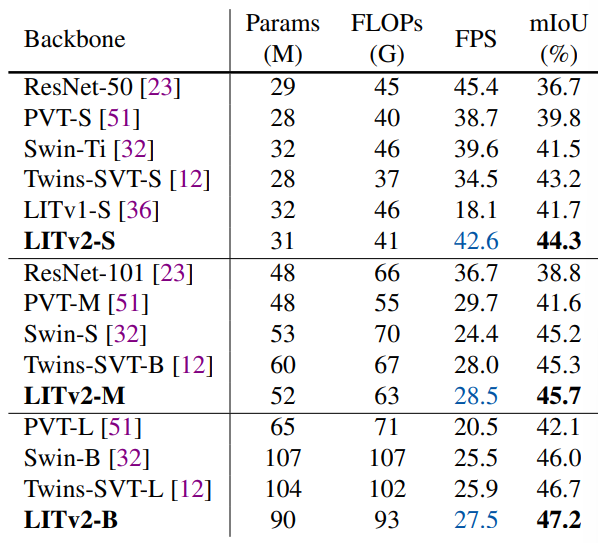
본 논문에서는 GPUs에서 빠른 속도를 내면서 효율적인 vision Transformer backbone인 LITv2를 소개하였고, 이는 ImageNet과 downstream task에서 SoTA에 비해 뛰어난 성능을 보여주었다. 또한 특히 고해상도 이미지에서 효율적인 HiLo attention을 제안하였다. HiLo attetnion은 경쟁력 있는 성능을 보여주면서도 FLOPs, throughput, memory consumption에서 장점을 얻을 수 있었다. 향후 작업에는 더 나은 성능을 위해 convolutional stem과 overlapping patch embedding을 통합하거나 음성 인식과 비디오 처리와 같은 더 많은 작업에서 HiLo를 확장하는 것이 포함될 수 있다.
[Ablastion Study]
By default, the throughput and memory consumption are measured on one RTX 3090 GPU with a batch size of 64 under the resolution of 224 x 224.
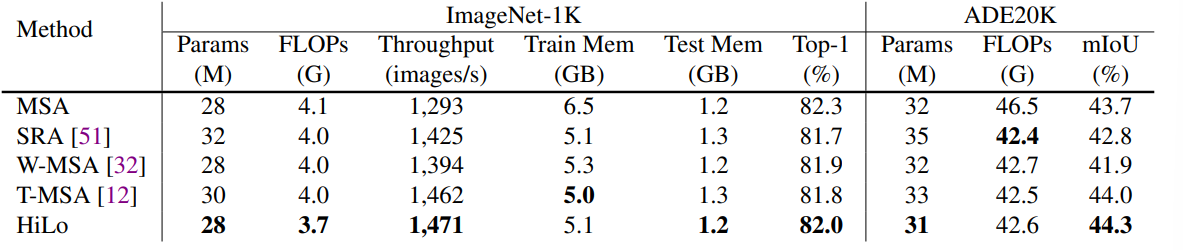
Comparing HiLo with other attention mechanisms

Effect of alpha
Effect of architecture modifications
Spectrum analysis of HiLo
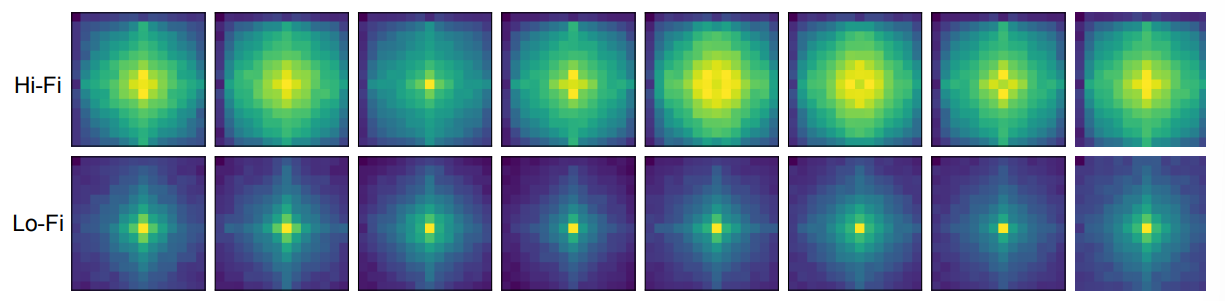
Hi-Fi와 Lo-Fi attention의 output feature map에 Fast Fourier Transform (FFT)를 적용하여 frequency component의 강도를 시각화하였다. 시각화는 Hi-Fi는 고주파수, Lo-Fi는 저주파수에 초점을 맞춘다는 것을 보여준다. 이는 단일 attention layer에서 feature map의 고주파와 저주파를 분리하려는 목표와 일치한다.
Speed and performance comparisons with more ViTs on different GPUs

Throughput comparisons with more attention mechanisms on CPUs and GPUs

특히 CPU testing에서 HiLo가 SRA에 비해 1.4배 빠르고, local window attention에 비해 1.6배 빠르고 VAN에 비해 17.4배 빠르다. (CPU와 GPU의 처리속도 순위가 다른데, 이를 분석하면 어떤 특성이 CPU와 GPU에서의 연산을 다르게 하는지 알 수 있을 것 같다.)