본 논문을 읽고 요약한 내용이며 잘못 해석한 내용이 있을 수 있습니다. 설명에 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
[Abstract]
본 논문의 저자는 latency-accuracy trade-off에서 SOTA를 달성하고 있는 hybrid vision transformer architecture인 FastViT를 소개하였다. 끝으로는 FastViT를 이루고 있는 block 중 하나인 RepMixer라고 불리는 novel token mixing operator를 소개하였다. RepMixer는 네트워크에서 skip-connection을 제거함으로써 메모리 접근 비용을 줄이기 위해 structural reparameterization을 사용하였다. 또한 train time overparametrization과 accuracy를 높이기 위해 large kernel convolution을 적용하였고, 실험적으로 이러한 선택이 latency를 줄이는 데 효과가 있음을 입증하였다. 기존의 모델과 비교했을 때 ImageNet dataset에서 같은 정확도를 달성하면서 더 빠른 속도를 보여준다. 또한 image classification, detection, segmentation, 3D mesh regression과 같은 다양한 task에서 mobile, desktop GPU 모두에서 유의미한 latency 개선을 보여준다.
[Motivation]
효율적인 네트워크를 설계하면서 높은 정확도를 설계하기 위해 Convolution과 transformer구조를 병합하는 하이브리드 방식이 주로 등장하고 있다.최근 공개된 Metaformer 구조는 skip connection이 있는 token mixer와 다른 skip connection이 있는 FFN으로 구성되는데, 이러한 skip connection 구조는 메모리 액세스 비용이 발생해 상당한 오버헤드를 발생시킨다. 따라서 본 논문에서는 이러한 구조적인 오버헤드를 Reparametrization 기법으로 해결하고자 하였다.
[Methodology]
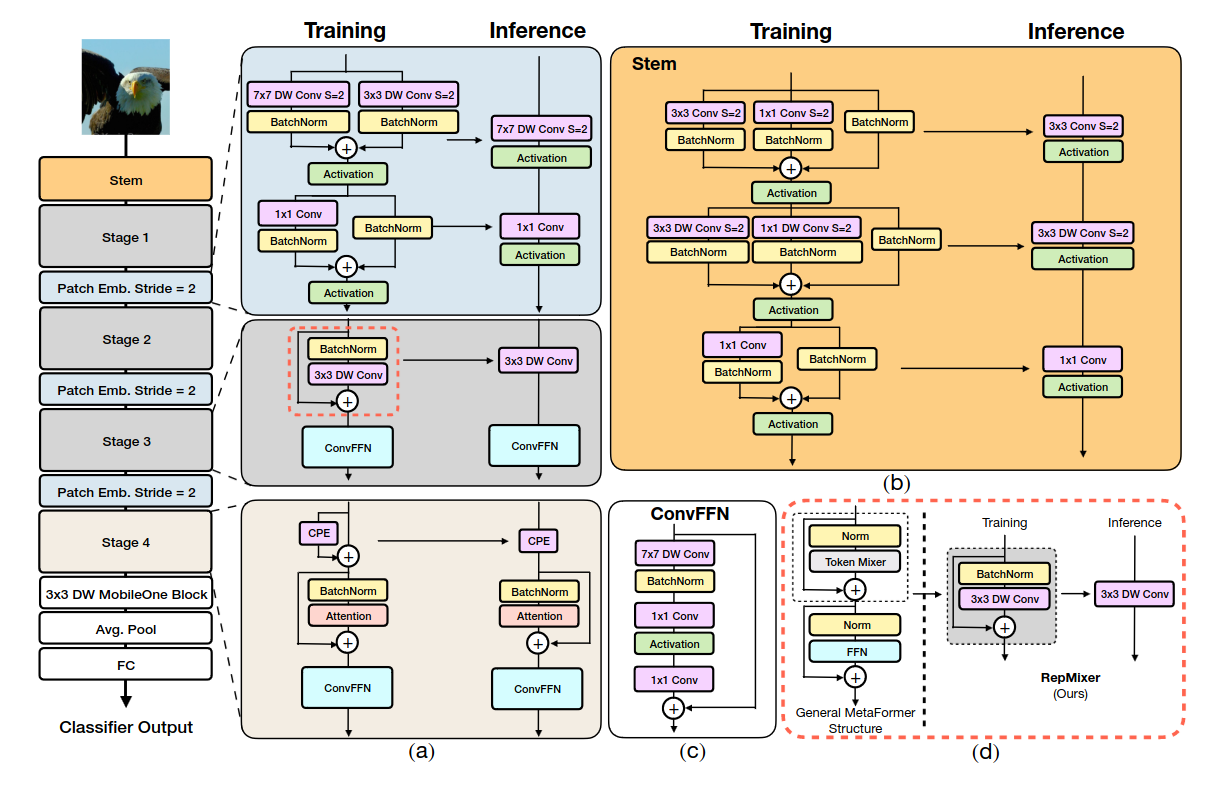
Reparameterizing Skip Connections
RepMixer
Convolutional mixing은 ConvMixer에서 처음으로 소개되었다.
(ConvMixer는 ViT의 성능이 transformer 아키텍처로 인한 것인지, 아니면 input representation으로 patch를 사용한 것이 영향을 끼쳤는지에 대해 탐색하는 논문. patch embedding layer 이후 반복되는 단순한 convolutional block으로 구성된 간단한 구조)
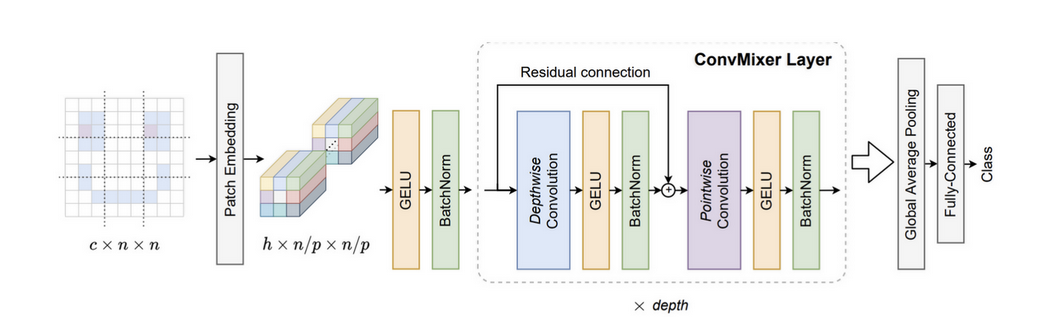
ConvMixer Layer는 위의 그림에서 보이는 것과 같이 input tesor를 X라고 할때,
Y = BN(\sigma(DWConv(X)) + X로 구성되어 있다.
여기서 sigma는 non-linear activation (그림에서는 GELU), DWConv은 depthwise convolutional layer를 의미한다. 이러한 block이 RepMixer에서 효과적이기 때문에 간단히 연산을 rearrange하고, non-linear activation을 제거하여
Y = DWConv(BN(X) + X 와 같이 식을 구성하였다. 이렇게 디자인한 이유는 Inference시 Figure 2d 와 같이 Y=DWConv(X)로 바뀔 수 있기 때문이다.
Positional Encoding
저자들은 동적으로 생성되고 input token의 local neighborhood에서 동작하는 conditional positional encoding을 사용하였다. 이러한 encoding은 depth-wise convolution operator의 결과로 생성되고 patch embedding에 추가된다.이 작업에서는 non-linearity가 없어 reparametrized될 수 있다.
Linear Train-time Overparameterization
Efficiency를 더욱 증가시키기 위해, 모든 dense k x k conolution을 그것의 factorized version으로 대체하였다. 즉, k x k depthwise follwed by 1 x 1 pointwise convolution 으로 대체하였다. 그러나 factorization으로 인한 적은 parameter수는 model의 capacity를 감소시킬 수 있다. 이를 증가시키기 위해 MobileOne에서 소개된 linear train-time overparameterization을 사용하였다.
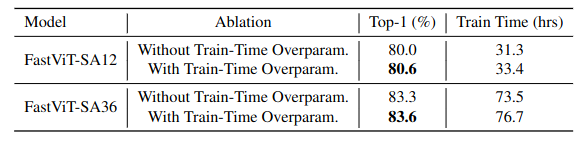
그러나 train-time overparamaterization은 추가된 분기의 오버헤드로 trainig time이 증가하는 결과를 보인다. 따라서, dense k x k convolution with factorization 부분만 대체하였다. (이러한 layer는 convolutional stem, patch embedding, projection layer에서 발견되나 일부만 선택하여 대체)
Large Kernel Convolutions
RepMixer의 receptive field는 self-attention token mixer에 비해 local이다. 그러나, self-attention 기반의 token mixer는 계산량이 매우 많다. self-attention을 사용하지 않는 초기 stage에서 receptive field를 효율적으로 개선하는 방법은 deptwise large kernel convolution을 통합하는 것이다. 따라서 FFN 및 patch embedding layer에 depthwise convolution을 도입한다.
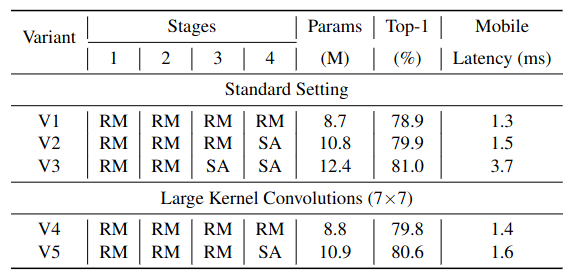
Table 4의 V3와 V5를 비교해보면, V3가 V5에 비해 0.4%의 작은 정확도 증가를 보이면서 모델 사이즈가 11.2% 크고, latency가 2.3배 높은 것을 볼 수 있다. V2와 v4를 비교해봐도 얻는 accuracy에 비해 standard setting이 효율적이지 못한 것을 알 수 있다.
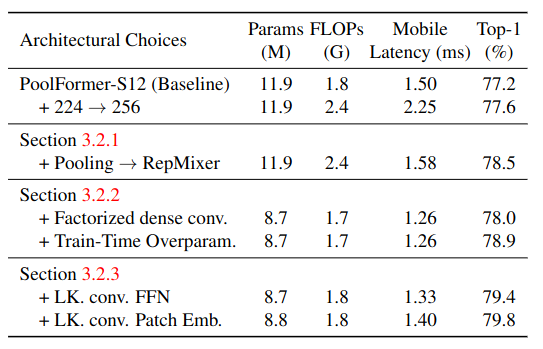
Table 1의 LK.conv.FFN과 LK.conv.Patch Emb. 결과를 보면 전체적으로 large kernerl convolution이 정확도 개선을 보인 것을 알 수 있다.
FFN과 patch embedding layer의 구조는 Figure 2와 같다. FFN block은 ConvNeXt block과 비슷하나 몇 가지 차이가 있다.
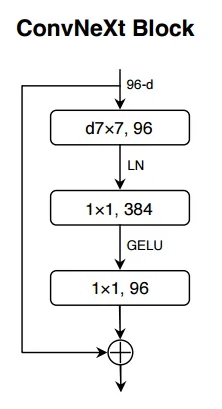
ConvNeXt Block에서 LN을 사용하는 것과 반대로 BN을 사용한다. 이는 이전 레이어와 융합될수 있기 때문이다. 또한 LN을 사용할 떄는 적절한 tensor layout을 얻기위해 적절한 변형 작업이 필요하다. 그러나 이렇게 대체하면 추가적인 reshape operation이 필요하지 않다.
[Datasets]
Image Classification : ImageNet-1K
Robustness Evaluation : ImageNet-A, ImageNet-R, ImageNet-Sketch, ImageNet-C
3D Hand mesh estimation : FreiHAND
Semantic Segmentation : ADE20k
Object Detection : MS-COCO
[Result]
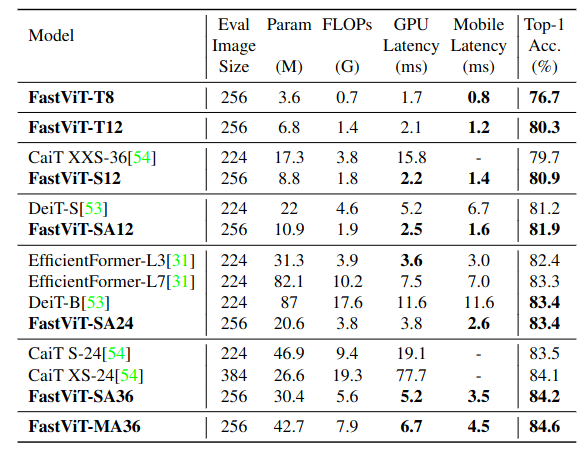
Image Classification
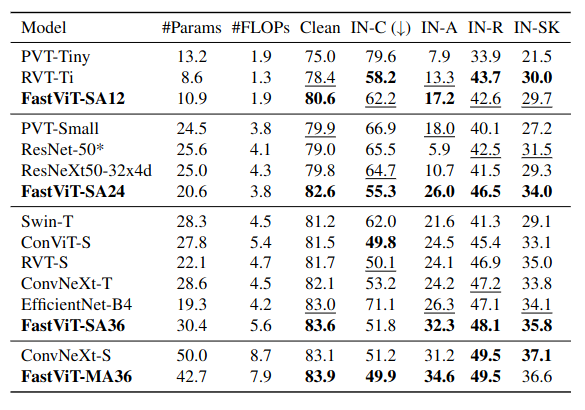
Robustness Evaluation
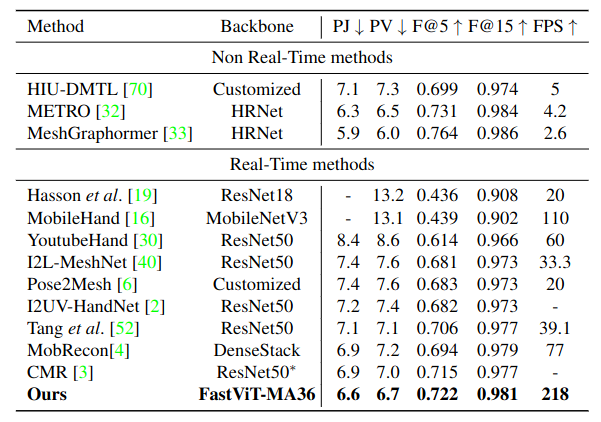
3D Hand mesh estimation
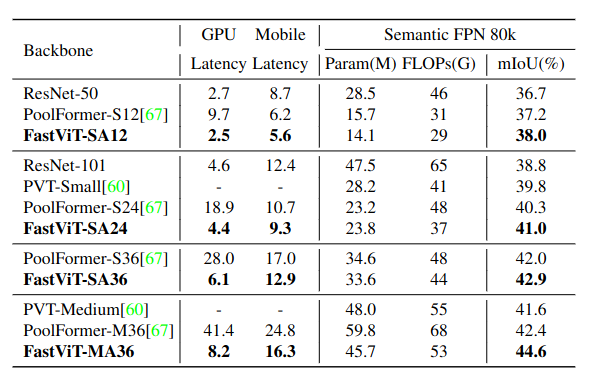
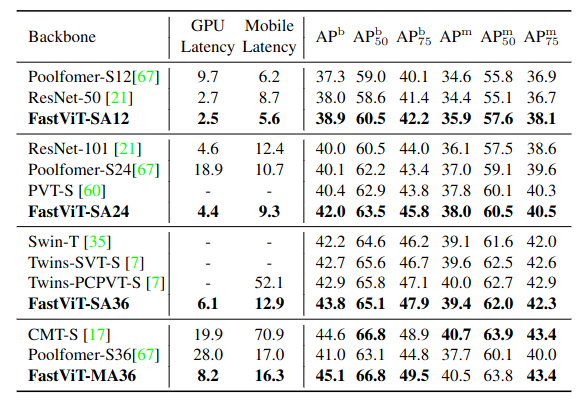
Semantic Segmentation and Object Detection
[Limitation]
[Idea]