본 논문을 읽고 요약한 내용이며 잘못 해석한 내용이 있을 수 있습니다. 설명에 오류가 있다면 댓글로 알려주시면 감사하겠습니다.
[Introduction]
최근 ViT가 좋은 성능을 보이며 image classification, object detection, semantic segmentation과 같은 다양한 computer vision task에 적용되고 있다. 그러나 여전히 deployment 관점에서 ViT는 CNN에 비해 훨씬 느려 CNN이 지배적이다. 많은 연구에서 ViT의 high frequency 딜레마를 극복하고자 노력하였다. 그러나 대부분의 hybrid 구조들은 단순히 CNN을 쌓은 이후 마지막에 Transformer를 ㅈ거용하는 방식이다. 이러한 구조는 downstream task에서 성능 포화를 불러온다. 더욱이 선행 연구에서 CNN과 Transformer block은 efficiency와 performance를 동시에 만족시키지 못한다는 것을 발견했다.
이러한 문제점을 해결하기 위해 저자들은 효율적인 Transformer를 설계하기 위한 세가지 요소 NCB, NTB, NHS를 제안하였다.

제안된 구조는 latency-accuracy trade-off에서 가장 우수하다.
본 논문의 주요 기여는 다음과 같다.
- 효과적인 convolution block과 transformer block, i.e. NCB와 NTB를 제안하였다. Next-ViT는 NCB와 NTB를 효과적으로 쌓은 hybrid 구조이다.
- hybrid 구조를 설계하는 새로운 관점을 제시하였다.
- 다양한 실험을 통해 Next-ViT의 우수성을 입증하였다. SOTA를 능가하는 성능을 보인다.
[Methods]

저자가 제안한 모델의 전체 구조는 Figure 2와 같다. 선행 연구에서 제안된 Hybrid 모델들은 CNN block을 연속적으로 쌓고 그 이후 Transformer block을 쌓는 형태로 설계되었다. 저자는 이러한 Hybrid 구조가 downstream task에서 성능 포화를 가지고 온다고 생각하였다. 따라서 각 스테이지에서 두 가지를 결합한 형태를 사용하였다. 본 논문에서 제안한 Next-ViT는 Next Convolution Block (NCB), Next Transformer Block (NTB)로 구성되어 있으며 Next Hybrid Strategy (NHS)를 통해 탐색되었다. Next-ViT는 hierarchical pyramid architecture를 따라 구성되었다. 전체적인 구조는 Patch Embedding과 각 스테이지의 convolution 혹은 transformer block으로 이어진다.
Next Convolution Block (NCB)

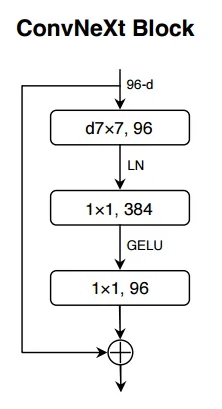
저자들은 NCB를 제안하기위해 고전적으로 제안되었던 구조들을 검토하였다. Figure 3(a)는 ResNet에서 제안된 BottleNeck block으로 내재된 inductive bias와 deployment-friendly 특성으로 대부분의 하드웨어에서 오랜 기간 사용되었다. 그러나 Transformer block에 비해 부적절하다. ConvNeXt block은 Transformer block의 구조를 모방하여 BotteNeck을 수정한 것으로 성능 향상을 보였으나 TensorRT, CoreML에서 제한적이다. (7x7 depthwise convolution, LayerNorm, GELU) Transformer block은 좋은 성능을 보이지만 attention mechanism의 계산 복잡도로 인해 inference speed는 CNN-based block에 비해 느리다.
이러한 점을 극복하여 Transformer block의 성능을 내며 Bottleneck의 배포 측면에서의 장점을 가져가는 Next Convolution Block (NCB)를 제안하였다. NCB는 일반적인 Transformer block의 구조를 차용하되, attention 연산을 줄이기 위해 새로운 Multi-Head Convolutional Attention (MHCA)를 적용하였다. (deployment-friendly)
최종적인 NCB의 구조는 MHCA + MLP로 Transformer block의 패러다임을 따른다.
Multi-Head Convolutional Attenttion (MHCA)

저자는 attention-based token mixer의 high latency 딜레마를 해결하기 위해, 효율적인 Convolutional Attention (CA)를 활용한 어텐션 메커니즘을 제안하였다.
효과적인 local representation learning을 위해 MHSA와 마찬가지로 다중 헤드 패러다임을 사용하였다.

MHCA는 h개의 하위공간의 정보를 캡처한다. z = [z1, z2, ...,zh]는 input feature z를 채널 차원에서 multi-head form으로 나누는 것을 의미한다. 다중헤드 사이의 정보 상호작용을 촉진하기 위해, projection layer (W)를 장착한다.

CA는 single-head convolutional attention으로 위의 식과 같이 인접한 토큰과 trainable parameter W의 내적으로 정의된다. CA는 local receptive field에서 trainable parameter W를 반복적으로 최적화하여 다른 토큰 사이에서 유연하게 학습할 수 있다.
정확한 구조는 Figure 4와 같다. MHCA는 group convolution (multi-head convolution)과 point-wise convolution (conv 1x1)로 구성된다. TensorRT의 다양한 데이터 타입에서 빠른 inference를 위해 head dim은 32로 설정하였다.
추가적으로, 빠른 추론속도를 위해 전통적인 구조에서 사용하는 LN과 GELU대신 BN과 ReLU를 사용하였다.
Next Transformer Block (NTB)

Transformer block은 global 정보를 담고있는 low-frequency signla을 잘 캡처하는 특징을 가지고 있다. 그러나 Figure 5에서 볼 수 있듯 high-frequency 정보는 담지 못한다. 실제 인간의 시각 시스템에서 서로 다른 주파수의 신호는 정확한 특징 추출을 위해 융합하여 사용된다.
이러한 관찰에 영감을 얻어 다양한 주파수의 신호를 감지하면서 경량화된 Next Transformer Block (NTB)를 제안하였다.

제안된 구조는 Figure 6과 같다. NTB는 먼저 E-MHSA를 통해 low-frequency signal을 캡처한다.

식으로 나타내면 위와 같다. SA는 Linear SRA에서 차용한 spatial reduction이다.

P_s는 공간차원을 downsampling하기 위한 것으로 stride를 s로 한 avg-pool 연산을 의미한다. attention 연산 전에 avg-pooling을 적용하여 연산량을 줄이고자 하였다. 저자들은 E-MHSA의 시간 소비가 채널 수에 큰 영향을 받는다는 것을 관찰하였다. 따라서 attention 전에 conv 1x1을 진행하여 채널 차원을 줄이고 inference를 가속화하고자 하였다. r은 channel reduction을 의미한다.
이후, multi-frequency signal을 캡처하기 위해 MHCA 모듈을 적용시켰다. 이러한 구조는 high-low frequency의 정보를 융합할 수 있도록 한다. 마지막으로 MLP layer를 붙였다. 여기서도 NCB에서와 마찬가지로 LN과 GELU 대신 BN과 ReLU를 적용하였다.
Next Hybrid Strategy (NHS)
선행 연구들은 CNN과 Transformer를 결합한 구조가 배포에 효과적임을 보여준다.

Figure 7(b)(c)를 보면 대부분의 선행 연구에서 각 스테이지에서는 CNN, Transformer만을 사용하고 마지막 스테이지에서만 Transformer를 쌓는 방식으로 설계되었음을 알 수 있다. 하지만, 이러한 방식은 downstream task에서 효과적이지 않다. classification은 단순히 마지막 output을 사용해 예측을 진행하지만 segmentation, object detection과 같은 downstream task의 경우 각 스테이지에서 어떤 feature를 추출하는지에 따라 성능이 결정되기 때문이다.
따라서 저자들은 NCB와 NTB를 (N+1) * L 패러다임으로 쌓는 Next Hybrid Strategy (NHS)를 제안하였다. 먼저, 각 스테이지에서 global information을 캡처할 수 있게 하기 위해 (NCB x N + NTB x 1) 패턴으로 설계하였다. 특히 NTB block은 각 스테이지에서 global representation을 학습하기 위해 스테이지에 마지막에 배치되었다.

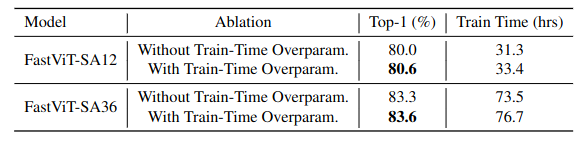
어떤 구조가 효과적인지 알아보기 위해 여러가지 조합에 대한 실험을 진행하였다. C는 한 스테이지가 모두 convolution block으로 구성된 것, T는 한 스테이지가 모두 Transformer block으로 구성된 것, H_N은 NHS로 설계된 것을 의미한다. 공정한 비교를 위해 TensorRT latency가 비슷할 때 downstream task에서의 정확도를 비교하였다. Table 1을 보면 CHHH로 설계했을 때 가장 좋은 성능을 보였다.
또한 큰 모델에서도 이러한 구조가 효과적인지 알아보기 위해 실험을 진행하였다.

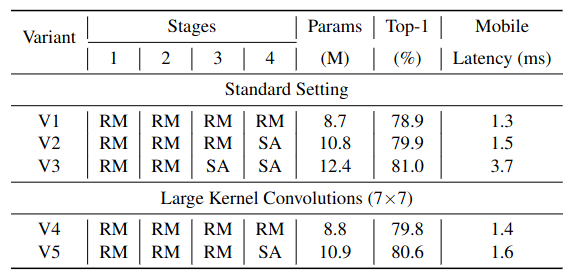
우선 Table 2의 윗부분을 보면 N의 개수를 늘려 크기를 조정했을 때 성능 포화에 달성한 것을 볼 수 있다. 이는 N을 늘려 크기를 늘리는 것은 좋은 방법이 아님을 의미한다. 따라서 (NCB X N + NTB X 1) 패턴을 유지하고 이를 여러번 쌓는 방식으로 크기를 늘려 성능을 비교하였다. 그 결과 이러한 패턴이 더 좋은 성능을 나타냈다. 이는 이러한 패턴이 다양한 주파수의 신호를 조합하는 것이 좋은 질의 representation learning으로 이어짐을 의미한다. Table 2에서 N=4일 때 performance-latency trade-off가 가장 우수했다.

식으로 나타내면 위와 같다.
Next-ViT Architectures

SOTA와의 공정한 비교를 위해 S/B/L 크기로 모델을 설계하였다. C는 output channel, S는 각 스테이지의 stride를 의미한다. 또한 r은 0.75, s는 [8, 4, 2, 1]로 사용하였다.
[Experiments]
ImageNet-1K Classification

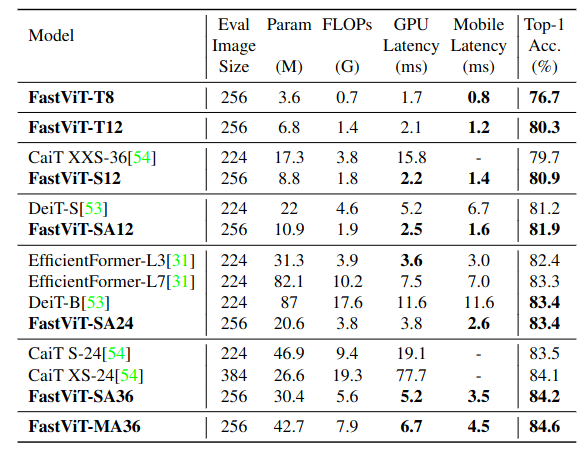
ImageNet-1k dataset에서 모델 크기에 따라 다양한 SOTA 모델과 performance-latency trade-off를 비교하였다.
Next-ViT-S와 CMT-XS, Twins-SVT-S, ResNet101 모델과 비교한 결과 더 빠른 속도를 내면서 더 좋은 성능을 나타냈다. 여기서도 볼 수 있듯이 파라미터와 FLOPs가 더 많더라도 latency가 더 빠를 수 있다.
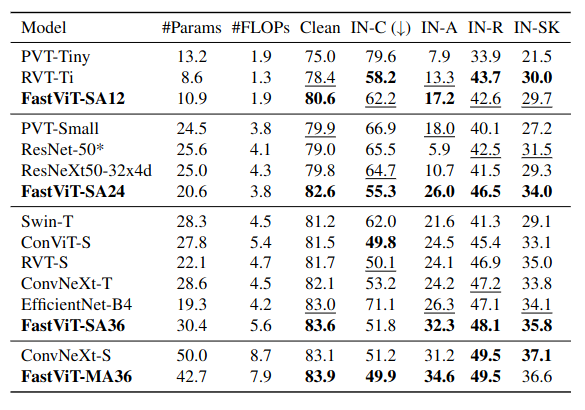
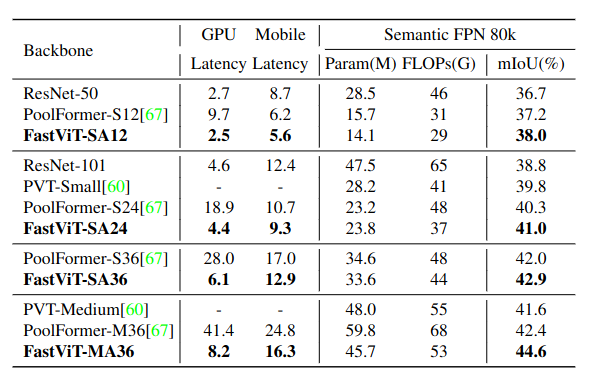
ADE20K Semantic Segmentation

Detection과 segmentation task에서 Mask R-CNN과 Upernet의 일부 모듈로 인해 TensorRT와 CoreML로 변환하는 것이 쉽지 않아 공정한 비교를 위해 backbone latency만을 측정해 비교하였다. latency 측정에서는 input size를 512 x 512로 사용하였다.
Object Detection and Instance Segmentation

Ablation Study and Visulaization
Next-ViT를 더 잘 이해하기 위해 Fourier spectrum과 heatmap을 사용해 분석하였다.
Impact of Next Convolution Block

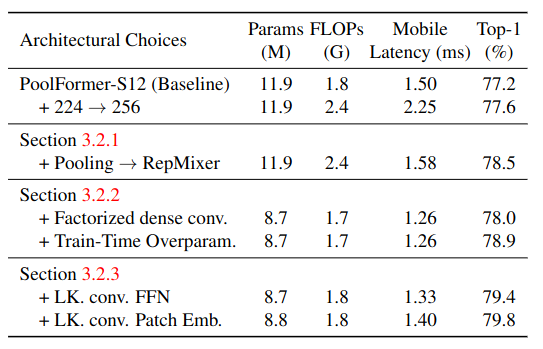
NCB의 효과를 입증하기 위해 NCB를 다른 block으로 대체하여 실험을 진행하였다. 공정한 비교를 위해 TensorRT latency를 비슷하게 유지하였다. Table 7을 보면 NCB가 가장 우수한 성능을 보임을 알 수 있다.
Impact of Different Shrink Ratios in NTB

또한 shrink ratio r의 영향을 알아보기 위해 실험을 진행하였다. Table 8을 보면 r이 작아질수록 latency가 줄어듬을 알 수 있다. 또한 r이 0.5, 0.75일 때 r=1일때보다 더 좋은 성능을 보였다. 이는 multi-frequency를 융합한 것이 더 좋은 성능을 낸다. (r은 E-MHSA 모듈의 채널 수로, r=1일때는 pure transformer를 의미한다. 저주파만 감지하는)
Impact of Normalization and Activation

서로 다른 normalization layer와 activation function의 영향에 대한 실험도 진행하였다. LN과 GELU를 같이 사용하는 것이 더 좋은 성능을 냈으나 높은 latency를 보였다. 반면, BN과 ReLU는 가장 좋은 latency/accuracy trade-off를 보였다.
Visualization

Next-ViT의 표현능력을 보기 위해 Fourier spectrum, heat map을 이용해 output feature를 시각화하였다. Figure 5(a)를 보면 ResNet은 high-frequency, Swin은 low-frequency만을 캡처하는 것을 볼 수 있다. 반면 Next-ViT는 두 신호를 잘 표현하고 있다. 또한 Figure 5(b)를 보면 Next-ViT가 global한 정보를 더 잘 캡처하는 것을 볼 수 있다.
[Conclusion]
본 논문에서는 mobile device와 server GPU를 위한 효과적인 구조 Next-ViT를 제안하였다. 실험을 통해 Next-ViT가 SOTA에 비해 latency/accuracy trade-off가 우수함을 입증하였다. 본 논문은 visual neural network에서 학문적 연구와 industrial deployment를 이어주는 역할을 했다는 데 의의가 있다.